
And courtesy of The Crazy Australian, this is the ESV New Testament:

(As The Crazy Australian noted, you can learn one thing immediately from that: the Third Person of the Trinity doesn't get as much stage presence as the Other Two in Holy Writ. Not really a surprise, but the point of Wordle is as much to visualise the obvious as it is to discover the not as obvious.)
Wordle works quite well with English, because most words don't have a lot of inflection, to multiply the instances of the concept you're looking for. In a language like Greek, on the other hand, lemmatisation—or as it's more often called in search engines, stemming—is essential. Otherwise, you get not one instance of "Jesus" or "state", but four or five, with no material difference.
Funnily enough, I do lemmatising. So what happens when you put the TLG through Wordle?

Images created by the Wordle.net web application are licensed under a Creative Commons Attribution 3.0 United States License.
Well, what you get is this:
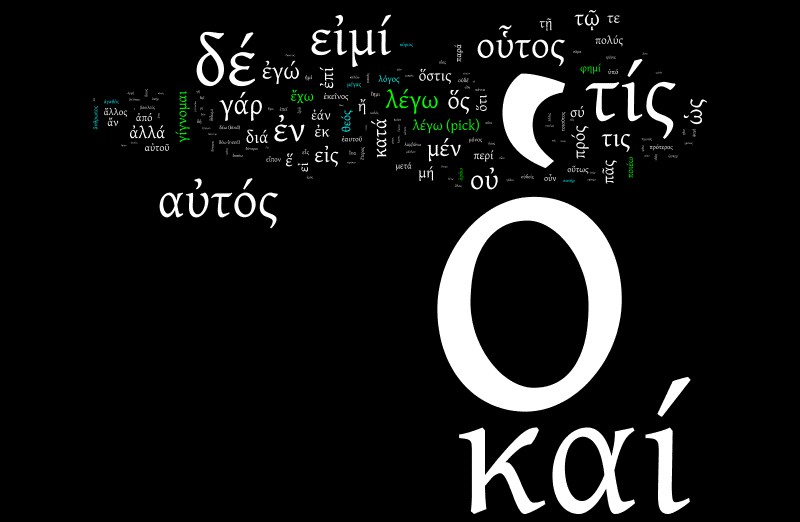
I've highlighted the top seven verbs in green, and the top seven nouns in green. You can see the nouns, right?
Of course you can't, because there's a whopping great big ὁ and another rather outsize καί there, crowding everything else out. And being told that Greek texts have a whole lot of instances of the and and is unlikely to be what most people are curious to know.
What we have here is the notion of stop words: grammatical words that don't convey a lot of content, and which search engines traditionally ignore. Wordle also ignores them, which is why you don't see a lot of the and and in English-language Wordles. But Wordle doesn't happen to be configured for Classical Greek.
So what happens if we whittle away at the stop words? Let's do this slowly. We'll start by getting rid of ὁ and καί.

Woah. Where did all that come from? You can see something now: θεός, λόγος, and if you really squint, ἄνθρωπος. But that's still making life too difficult, because there are more stop words to dismiss. I've highlighted the next batch in red: τίς, δέ, αὐτός, εἰμί, who?, but, he/himself, be. Of these, τίς "who?" is inflated through ambiguity with τις "someone"; because the lemmatisation is not disambiguated by context, a few word counts are more sizeable than they should be.
With those four out of the way, we have:
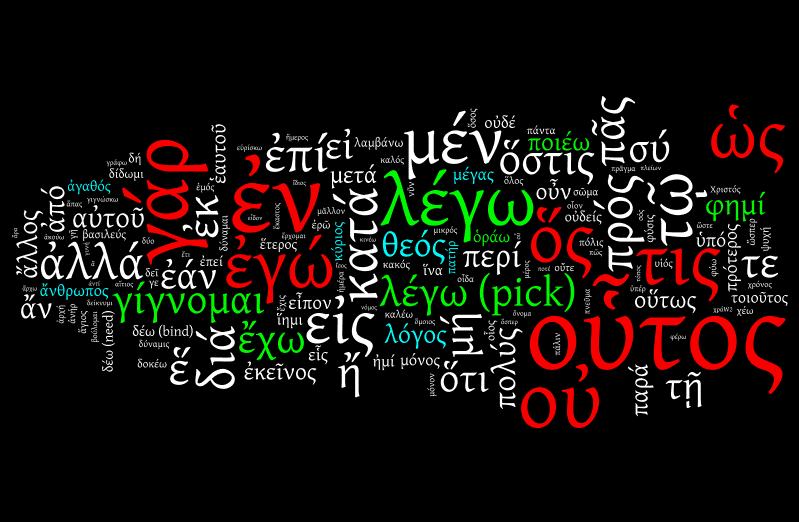
An improvement; you can see ἄνθρωπος now, and maybe even πατήρ "father" next to θεός "god". But we still can do better. We have eight more stop words that we don't really need to hear about: ἐγώ "I", ὡς "as, that", ὅς "who, that", τις "someone", οὐ "not", γάρ "because", ἐν "in", and οὗτος "this".
With them left out, we have:

Still better: you can make out ἔχις "viper" now, at the bottom left hand edge. Not that Greeks spent a lot of time talking about vipers; they just spent a lot of time using the verb ἔχει "has", which happens to be ambiguous with the dative of ἔχις. It's automated lemmatisation, this kind of thing can happen.
We have sixteen more stop words, and as you may have worked out, the easiest criterion is to bundle up all function words—prepositions, adverbs, conjunctions, interjections, pronouns. With some of the ambiguity inherent in the venture—is πᾶς "every" a pronoun or an adjective?—but we can keep slicing nonetheless:
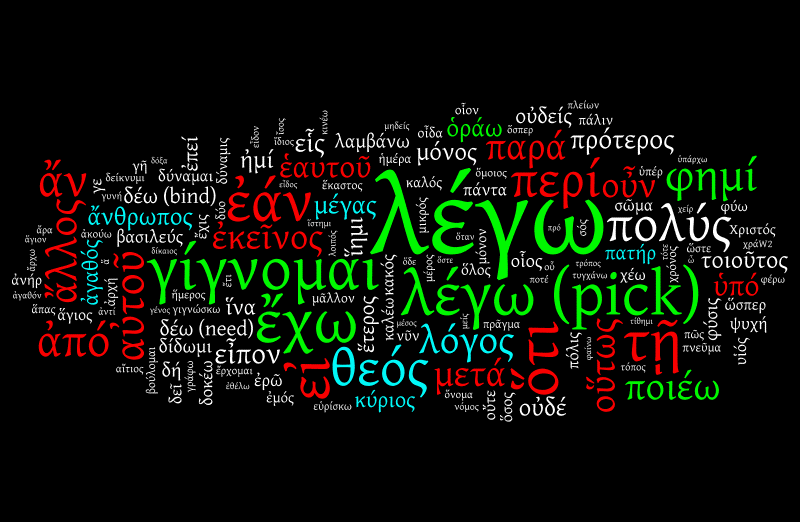
And again:

We're not making as much of a difference now; but notice that the screen is being crowded out by verbs: λέγω "say" (and "pick", as a synonym that used to be the same verb—just like "count" and "recount" in English); γίγνομαι "become", ἔχω "have". These are verbs, and are properly considered content words. But I already got rid of εἰμί "to be" (which as a copula is not a content word; and I'm happy to also throw out "have", "become" (close to a copula itself), and verbs for "say". (There is a lot of "he said she said" in the TLG, because there is a lot of narrative.)
If we get rid of those verbs?

And tidying up getting rid of the next hundred and fifty function words, which are a distraction as you squint for content:

You could argue there's still some guff there: ποιέω "do" doesn't tell you much more than ἔχω "have", and πολύς "much" doesn't really deserve its disproportionate size. But we have enough cleaned up that we can say now something about what the texts talk about. It's certainly a sight better than this:
So what do the TLG texts talk about? You may well be starting to come up with ideas if you can read Greek. But before you do, remember that there a whole lot of Christian texts in the TLG, and they quantitatively crowd the ancient texts out. The texts of John Chrysostom alone in the TLG are almost as sizeable as all surviving Ancient literature between Homer and Aristotle.
So yes, the TLG as a whole talks about God and logos a fair bit. But we'd expect that of John Chrysostom; it doesn't mean its what Plato or Homer talk about.
What'd be useful is to split up the corpus, say BC and AD, and see how they differ. Sounds like the next blog post to me...
Btw, I've been stamping out stop words, but stop words are of interest if you're looking at grammar; and Nikos Sarantakos did ask me to pony up the word counts that I was tossing out. So, for the TLG and the lemmatiser as of last night, these are the twenty five most frequent lemmata of Greek, with their textual frequency:
| πᾶς | 534,845 | every |
| ἕ | 547,255 | he |
| ἀλλά | 548,203 | but |
| διά | 561,813 | for |
| ἐπί | 566,238 | on |
| πρός | 566,476 | towards |
| κατά | 643,767 | by |
| εἰς | 694,035 | to |
| τῷ | 732,938 | therefore (ambiguous with "to the") |
| μέν | 762,890 | on the one hand |
| ἐγώ | 767,104 | I |
| ὡς | 771,416 | as, that |
| ὅς | 801,401 | who, that |
| λέγω | 811,330 | say |
| τις | 834,155 | someone |
| οὐ | 926,059 | not |
| γάρ | 951,810 | because |
| ἐν | 1,128,716 | in |
| οὗτος | 1,228,627 | this |
| αὐτός | 1,646,014 | he, himself |
| εἰμί | 1,704,651 | be |
| δέ | 2,265,028 | but |
| τίς | 2,624,172 | who? |
| καί | 5,765,491 | and |
| ὁ | 14,335,717 | the |
Of the lemmata we have not thrown out, θεός "god" is the 39th most frequent, with 388,933 instances.

 Loading...
Loading...
Πολύ καλό!
ReplyDeleteΑν το πιστεύεις, το έχω σκεφτεί καιρό, όλο έλεγα να στο προτείνω, κι όλο το ξεχνούσα!
Κι εγώ όποτε χρησιμοποιώ το wordle κάνω stemming & stop word elimination με το χέρι...
Ιmpressive... but what is this ε (the second item in the last list)?
ReplyDeleteStazy: Και γω το σχεδίαζα τουλάχιστον από τον Οκτώβριο. Μη νομίζεις βέβαια ότι και πάλι δεν τα περνάω με το χέρι...
ReplyDeleteNikos: ἕ is Homeric: see LSJ. E.g. Iliad 1.236: περὶ γάρ ῥά ἑ χαλκὸς ἔλεψε φύλλά τε καὶ φλοιόν, "for the bronze has stripped it on all sides of leaves and bark".
Outside the accusative ἕ, its Attic dative and genitive οἷ and oὗ are ambiguous with the much more common relative pronoun, which is why its counts are inflated.
Πολύ καλό Νίκο. Κάνε και κατά genre ή λογοτεχνικό είδος, θα έχει ενδιαφέρον.
ReplyDeleteAre we greeking it now or what?
ReplyDeleteAnyway, I did think of the Homeric ε, but this has a handful of occurences -saying that the counts are (merely) inflated is quite an understatement!
Shame the images have disappeared. This was an awesome post.
ReplyDeleteFortunately the Way Back Machine was allowed crawling at both domains, so here they are altogether, in the right sequence:
Deletehttp://imgur.com/a/90rUI
Originating from:
http://web.archive.org/web/20120307025152/http://www.thecrazyaustralian.com/wp-content/uploads/2008/06/new-testament.jpg
http://web.archive.org/web/20120415013923/http://www.tlg.uci.edu/~opoudjis/nicjpgs/2010-01-31/worlde1.gif
http://web.archive.org/web/20120415013839/http://www.tlg.uci.edu/~opoudjis/nicjpgs/2010-01-31/worlde2.gif
http://web.archive.org/web/20120415013913/http://www.tlg.uci.edu/~opoudjis/nicjpgs/2010-01-31/worlde3.gif
http://web.archive.org/web/20140602193516/http://www.tlg.uci.edu/~opoudjis/nicjpgs/2010-01-31/worlde4.gif
http://web.archive.org/web/20120415013802/http://www.tlg.uci.edu/~opoudjis/nicjpgs/2010-01-31/worlde5.gif
http://web.archive.org/web/20120415013732/http://www.tlg.uci.edu/~opoudjis/nicjpgs/2010-01-31/worlde6.gif
http://web.archive.org/web/20120415013745/http://www.tlg.uci.edu/~opoudjis/nicjpgs/2010-01-31/worlde7.gif
http://web.archive.org/web/20140602194216/http://www.tlg.uci.edu/~opoudjis/nicjpgs/2010-01-31/worlde8.gif
Submit your blog or website now for inclusion in Google and 300+ search engines!
ReplyDeleteOver 200,000 websites handled!
Submit RIGHT NOW with I NEED HITS!