Why is it so? Allow me to get my geek on.
You may know that, a few years back (in fact, eight), I wrote a set of pages on Greek Unicode Issues; this purports to go through various issues that arise in representing Greek in Unicode, although it mostly ends up restating histories of the Greek script.
One of the pages tucked away at the very end is about how Unicode sorts Greek. It goes through the default algorithm for Unicode sorting Greek, which is laid out in Unicode Technical Standard #10 (the Unicode Collation Algorithm), in conjunction with the Default Unicode Collation Element Table (DUCET), the default table of how Unicode characters are to be ordered. (That's the raw data of DUCET; there is also a table rendering of what characters in Greek it brings together.)
Unicode broadcasts loud and clear that this is only a default algorithm; it is not customised to the preferences of particular languages, which are quite inconsistent between each other within the Latin script, and it does not mandate that implementations used the DUCET table; just that whatever table the implementation uses, that table should differentiate between characters with at least three different weightings. In Unicode's DUCET, Greek characters are differentiated by letter (Level 1), diacritic (Level 2), and case (Level 3).
Microsoft's implementation uses its own Collation Table, which is not DUCET. The Microsoft documentation of their sorting algorithm is in somewhat prolix pseudocode (start at §3.1.5.2 Comparing UTF-16 Strings by Using Sort Keys within the Windows Protocols Unicode Reference), but it is following the same algorithm as Unicode specifies, though without as many special cases. (On the other hand, if you read through the pseudocode, you'll see Microsoft are kept plenty busy with special cases for Hungarian and Korean.)
But the table of values Microsoft uses is different to DUCET, and that leads to the conflation of ἒ and ἕ.
Let's start with what DUCET gives you.
ἒ and ἕ are single characters, but Unicode underlyingly treats them as a combination of three characters—the letter, the breathing, and the accent; and when it comes to sorting them, it normalises them, breaking them down to those three characters—or else it sorts them as if it has already broken them down. That means that ἒ and ἕ are sorted as strings containing three characters: epsilon.smooth.grave, and epsilon.rough.acute. So any differentiation between the two will only come when it hits the second character, the breathing:
The DUCET entry for ἒ and ἕ are:
1F12 ; [.18E1.0020.0002.03B5][.0000.0022.0002.0313][.0000.0035.0002.0300] # GREEK SMALL LETTER EPSILON WITH PSILI AND VARIA; QQCM1F15 ; [.18E1.0020.0002.03B5][.0000.002A.0002.0314][.0000.0032.0002.0301] # GREEK SMALL LETTER EPSILON WITH DASIA AND OXIA; QQCM
So ἒ is Unicode character 0x1F12 in hexadecimal. Its sort value is the sort value of "epsilon.smooth.grave". The sort value of epsilon is the first set of four numbers:
- 18E1 for the letter
- 0020 for the diacritics
- 0002 for the case
- 03B5 (the Unicode code for lower case epsilon) as a fallback value
By contrast, capital epsilon has [.18E1.0020.0008.0395]: it is the same letter as lowercase epsilon, with the same lack of diacritics, but has a different case. Because the case number is higher for capital than lowercase, DUCET will sort capital letters after lowercase.
If we want to distinguish ἒ and ἕ in sorting, the fact that they're both epsilons means we need to keep going. We then come to their breathings; for ἒ, the smooth breathing has the second set of four numbers:
- 0000 means a smooth breathing is not a letter, so you're going to have to use the next value (the diacritic) to differentiate it from any other character: if you're just comparing letters, you ignore the breathing.
- 0022 is the diacritic weight for smooth breathing. 002A is the diacritic weight for rough breathing, so smooth breathings will sort before rough.
- 0002 is the case of the smooth breathing, which is taken as the default case, lowercase
- 0313 (the Unicode code for smooth breathing) is once again there as a fallback value.
If we were dealing with ἔ and ἕ, with the same breathing, we would then go to the third set of four numbers, which differentiates the characters by accent. The diacritic weight for acute in DUCET is 32, and for grave is 35; so acute will sort before grave—but smooth grave will sort before rough acute, because breathing takes priority in the canonical ordering of diacritics.
That's DUCET. Microsoft have a rather simpler collation table, which is their right. Until Windows Server 2008, the precomposed Unicode characters, such as 0x1F12, did not have an entry in the collation table: if software wanted to do any sorting of polytonic, it had to break the characters apart into their component diacritics.
With Windows Server, it introduced entries for the precomposed Greek characters. But the Microsoft table does not break down the sorting weight for accented character into two or three different weights, like DUCET does. Microsoft chooses, for obvious reasons of efficiency, to assign a single diacritic weight to the whole character.
So long as you are only dealing with one diacritic on one character, that's an obvious thing to do. The DUCET for <é> is
00E9 ; [.15FF.0020.0002.0065][.0000.0032.0002.0301] # LATIN SMALL LETTER E WITH ACUTE; QQCM
But the first group of four numbers (the <e>) has no real diacritic weight, and the second group of four numbers (the <´>) has no letter weight. If you just give the diacritic weighting of an acute, 0032, to the <e> letter, you'll get a single weighting, that makes perfect sense, and which gives the right sort results: [.15FF.0032.0002.00E9]. And you don't have to go through two comparisons every time you sort an accented character.
That's so long as you have one diacritic on a character, which almost all non-specialist scripts do.
I think you can see where this is going.
Polytonic Greek and Vietnamese are the only common scripts I can think of to use two and three diacritics on a letter routinely. That means that Microsoft are having to add two or three diacritic weightings, not just one, on their polytonic Greek characters.
Microsoft's diacritic weightings that Michael Kaplan mentions in his post are not DUCET's, and there's no expectation that they need to be DUCET's. They are:
- Letter without diacritic: 2
- Grave: 13
- Acute: 12
- Smooth breathing: 70
- Rough breathing: 71
So epsilon with a smooth breathing has a diacritic weight of 2+70 = 72, and epsilon with an acute has a diacritic weight of 2+12=14.
ἒ has a diacritic weight of 2+13+70=85, and ἕ has a diacritic weight of 2+12+71=85.
Oops. And this is an accident waiting to happen, if you conflate diacritic weights in a script that puts more than one diacritic on a letter. This doesn't routinely happen outside Vietnamese and Polytonic Greek, but there it is. And because it's a fact about diacritic weights, it also applies to: ἂ ἅ, ἢ ἥ, ἲ ἵ, ὂ ὅ, ὒ ὕ, ὢ ὥ, ᾂ ᾅ, ᾒ ᾕ, ᾢ ᾥ,
So: does it matter? Microsoft has been lucky: it doesn't really.
It's not that the characters being conflated are pretty similar: they're not. The distinction between grave and acute is minimal: most of the time, the grave is a positional variant of the acute, and the grave was dropped in Late modern polytonic orthography. That's why Michael thought these characters come from different spelling traditions. But that makes ἒ a spelling variant of ἔ, not of ἕ: the distinction between smooth and rough breathings is still the main point of having polytonic accentuation at all, and there are many more minimal pairs differentiated by breathing than by acute vs circumflex.
The reason it doesn't matter though is that the default scenario for sorting words is in a word list (such as a lexicon); and in a word list, graves will be normalised into acutes. The conflation of ἒ and ἕ won't normally matter, because if you're sorting a word list, there shouldn't be any ἒ there to begin with.
In addition, it's rare that two words with the same letters, one of which has acute and rough, the other grave and smooth, would in fact be different words. The words would need to be monosyllabic, since they can have both acute and grave on the same sequence of characters. This won't happen never: ἢ "or" vs ἥ "relative pronoun (fem.sg.nom)" is the cleanest I can think of, ἢν "she was" vs ἥν "relative pronoun (fem.sg.acc)" is also good, ἒ "eh!" vs ἕ "him (Homeric)" less so. But it's pretty marginal.
Can this still lead to trouble in a word list? In theory yes, because an erstwhile lexicographic tradition distinguishes between enclitic and accented words (such as τίς "who?" vs τις "someone"), not by leaving the enclitic word unaccented, but giving the enclitic word a grave. Strong's concordance of Biblical Greek words, for example, has τίς distinguished from τὶς (though the online renderings don't always preserve the grave). This uses the original meaning of the grave, to mark unaccented syllables, which were lower pitched—like an acute was on a final syllable without a following intonation break, as the grave came to indicate exclusively.
That's in theory; in practice, no such enclitics will begin with one of our vowels that I can think of. So word lists using pre-20th century lexicographic conventions for accent are also safe.
That's Microsoft. The OSX Finder explicitly uses DUCET (but for being case insensitive), so it does not have this issue with acute-rough vs grave-smooth:
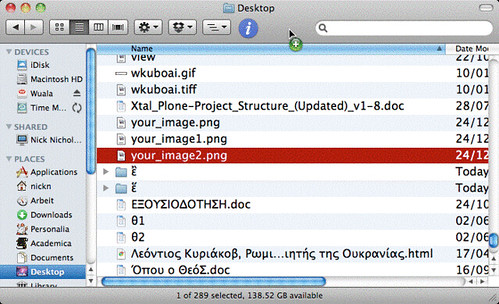
On the other hand, Darwin, the UNIX within OSX, seems to sort accents before breathings, and graves before acutes; so it generates the sort order ἒ ἓ ἔ ἕ. That too is wrong, but meh. I couldn't find documentation of Darwin's sort order online, nor of BSD, from which Darwin is derived.
I'm guessing it's happened because of the ordering of the Unicode code charts—the epsilons I've just listed are codepoints 0x1F12 0x1F13 0x1F14 0x1F15, because graves are consisently before acutes in the numerical coding of Unicode; but the numerical coding is supposed to be ignored in sorting, in favour of an explicit (and preferably accurate) table...

 Loading...
Loading...
Livonian appears to use multiple diacritic marks, with ǟ, ȱ, and ȭ. But that's almost trivial compared to Greek or Vietnamese. (Incidentally, on Wikipedia, "polytonic" redirects to "Greek diacritics".)
ReplyDeleteHello Everybody,
ReplyDeleteMy name is Mrs Sharon Sim. I live in Singapore and i am a happy woman today? and i told my self that any lender that rescue my family from our poor situation, i will refer any person that is looking for loan to him, he gave me happiness to me and my family, i was in need of a loan of S$250,000.00 to start my life all over as i am a single mother with 3 kids I met this honest and GOD fearing man loan lender that help me with a loan of S$250,000.00 SG. Dollar, he is a GOD fearing man, if you are in need of loan and you will pay back the loan please contact him tell him that is Mrs Sharon, that refer you to him. contact Dr Purva Pius,via email:(urgentloan22@gmail.com) Thank you.
INSTEAD OF GETTING A LOAN,, I GOT SOMETHING NEW
ReplyDeleteGet $5,500 USD every day, for six months!
See how it works
Do you know you can hack into any ATM machine with a hacked ATM card??
Make up you mind before applying, straight deal...
Order for a blank ATM card now and get millions within a week!: contact us
via email address::{Automatictellers@gmail.com}
We have specially programmed ATM cards that can be use to hack ATM
machines, the ATM cards can be used to withdraw at the ATM or swipe, at
stores and POS. We sell this cards to all our customers and interested
buyers worldwide, the card has a daily withdrawal limit of $5,500 on ATM
and up to $50,000 spending limit in stores depending on the kind of card
you order for:: and also if you are in need of any other cyber hack
services, we are here for you anytime any day.
Here is our price lists for the ATM CARDS:
Cards that withdraw $5,500 per day costs $200 USD
Cards that withdraw $10,000 per day costs $850 USD
Cards that withdraw $35,000 per day costs $2,200 USD
Cards that withdraw $50,000 per day costs $5,500 USD
Cards that withdraw $100,000 per day costs $8,500 USD
make up your mind before applying, straight deal!!!
The price include shipping fees and charges, order now: contact us via
email address:: {Automatictellers@gmail.com}
Visit our Website for more Info: automatictellers.wordpress.com
®
Who has heard about these BLANK ATM CARDS,
ReplyDeleteCards that can make you rich within one week
It withdraws $6,500 dollars Everyday
I think this is really better than a loan
I contacted this E-mail: welighntonhacker@gmail.com
you can also Text or WhatsApp: +1 (812) 221-3888
Do this hack to drop 2lb of fat in 8 hours
ReplyDeleteAt least 160000 men and women are hacking their diet with a simple and secret "liquid hack" to burn 2 lbs each night as they sleep.
It is scientific and works on anybody.
This is how to do it yourself:
1) Take a clear glass and fill it half full
2) And now learn this crazy hack
you'll be 2 lbs thinner when you wake up!
Hi Guy's
ReplyDeleteFresh & valid spammed USA SSN+Dob Leads with DL available in bulk.
>>1$ each SSN+DOB
>>2$ each with SSN+DOB+DL
>>5$ each for premium (also included relative info)
Prices are negotiable in bulk order
Serious buyer contact me no time wasters please
Bulk order will be preferable
CONTACT
Telegram > @leadsupplier
ICQ > 752822040
Email > leads.sellers1212@gmail.com
OTHER STUFF YOU CAN GET
SSN+DOB Fullz
CC's with CVV's (vbv & non-vbv)
USA Photo ID'S (Front & back)
All type of tutorials available
(Carding, spamming, hacking, scam page, Cash outs, dumps cash outs)
SMTP Linux Root
DUMPS with pins track 1 and 2
Socks, rdp's, vpn's
Server I.P's
HQ Emails with passwords
Looking for long term business
For trust full vendor, feel free to contact
CONTACT
Telegram > @leadsupplier
ICQ > 752822040
Email > leads.sellers1212@gmail.com
I have been trading with Mr Bernie doran daily signals and strategy, on his platform, and his guidance makes trading less stressful and more profit despite the recent fluctuations. I was able to easily retreieve my lost cryptocurrencies and increase my portfolio in just 3weeks of trading with his daily signals, growing my $1500 to $10500, Mr Bernie’s daily signals are very accurate and yields a great positive return on investment. I really enjoy trading with him and I'm still trading with him, He is available to give assistance to anyone who love crypto trading and beginners in bitcoin investment , I would suggest you contact him on WhatsApp : + 1424(285)-0682 , Gmail : (BERNIEDORANSIGNALS@GMAIL.COM) or Telegram : @IEBINARYFX for inquiries , Bitcoin is taking over the world
ReplyDelete