The corpus I'm using consists of a group of texts I've come to know well, the TLG; and a group of texts I know less well, the PHI #7 disc. The Thesaurus Linguae Graecae is a digital library of Ancient and Byzantine texts, which has been steadily moving forwards in time: it's increasing by around 3 million words a year. Counting words of data-entered text, including markup, hyphenated fragments, and symbols, it currently has close to 105 million word instances; if we restrict the count to just words of Greek, it has 95 million words. (That's your first indication that counting words is complicated.)
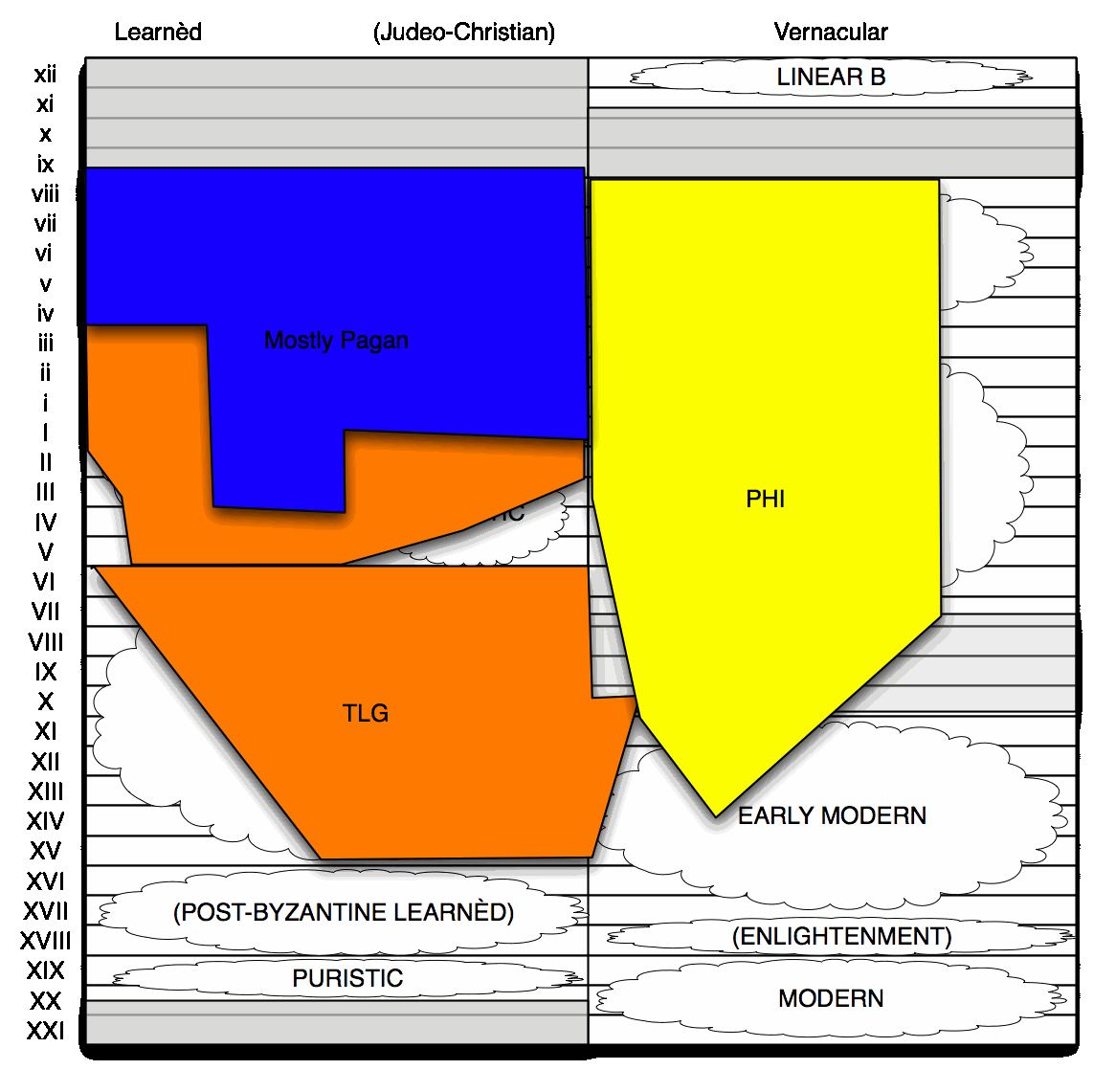
The TLG doesn't have all the text there is, but it does have a lot, and it's filling in texts as it goes. I'll reuse the grid I used for dictionary coverage of Greek to show how:
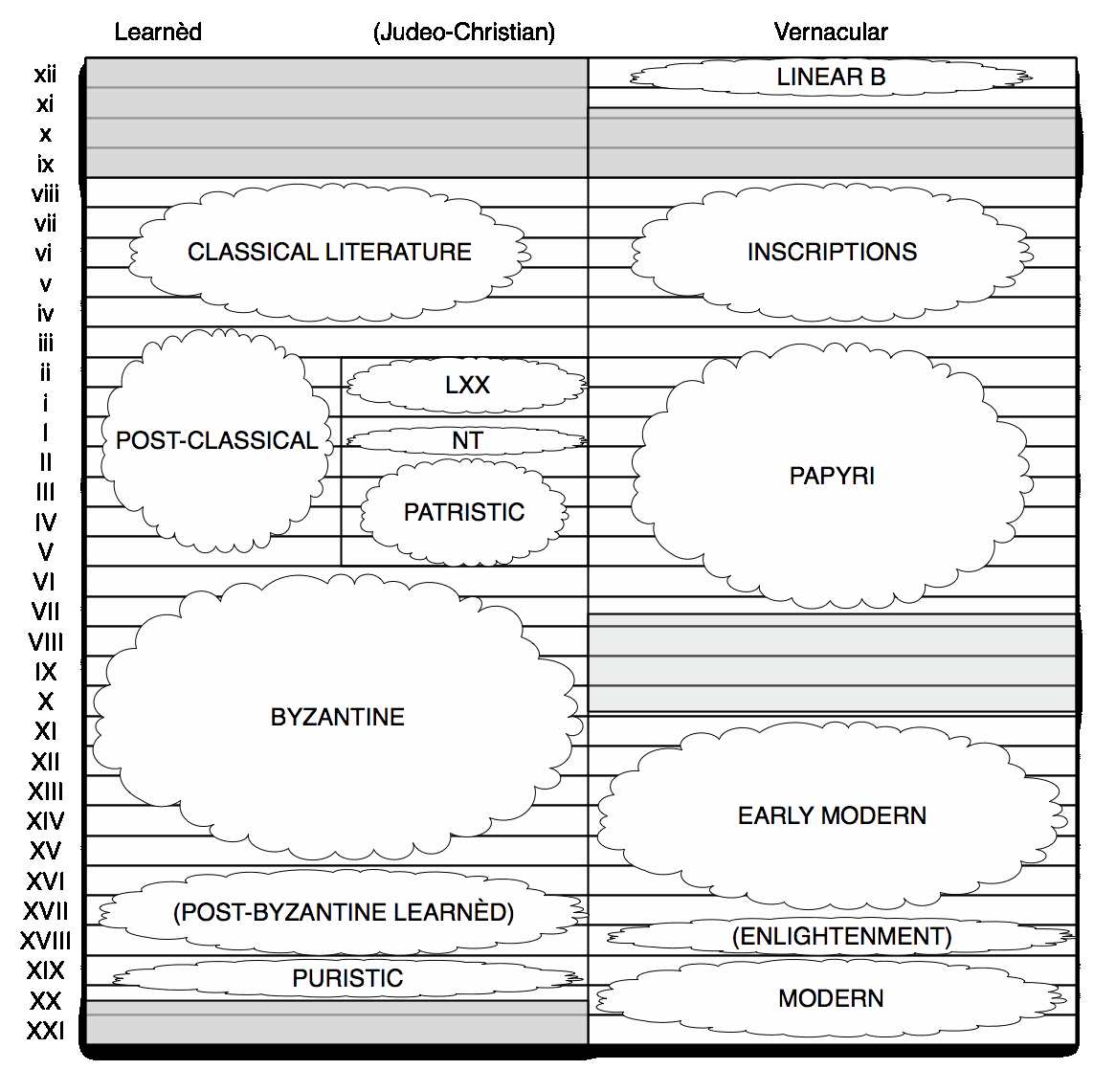
This is a crude representation of the current coverage of the TLG:
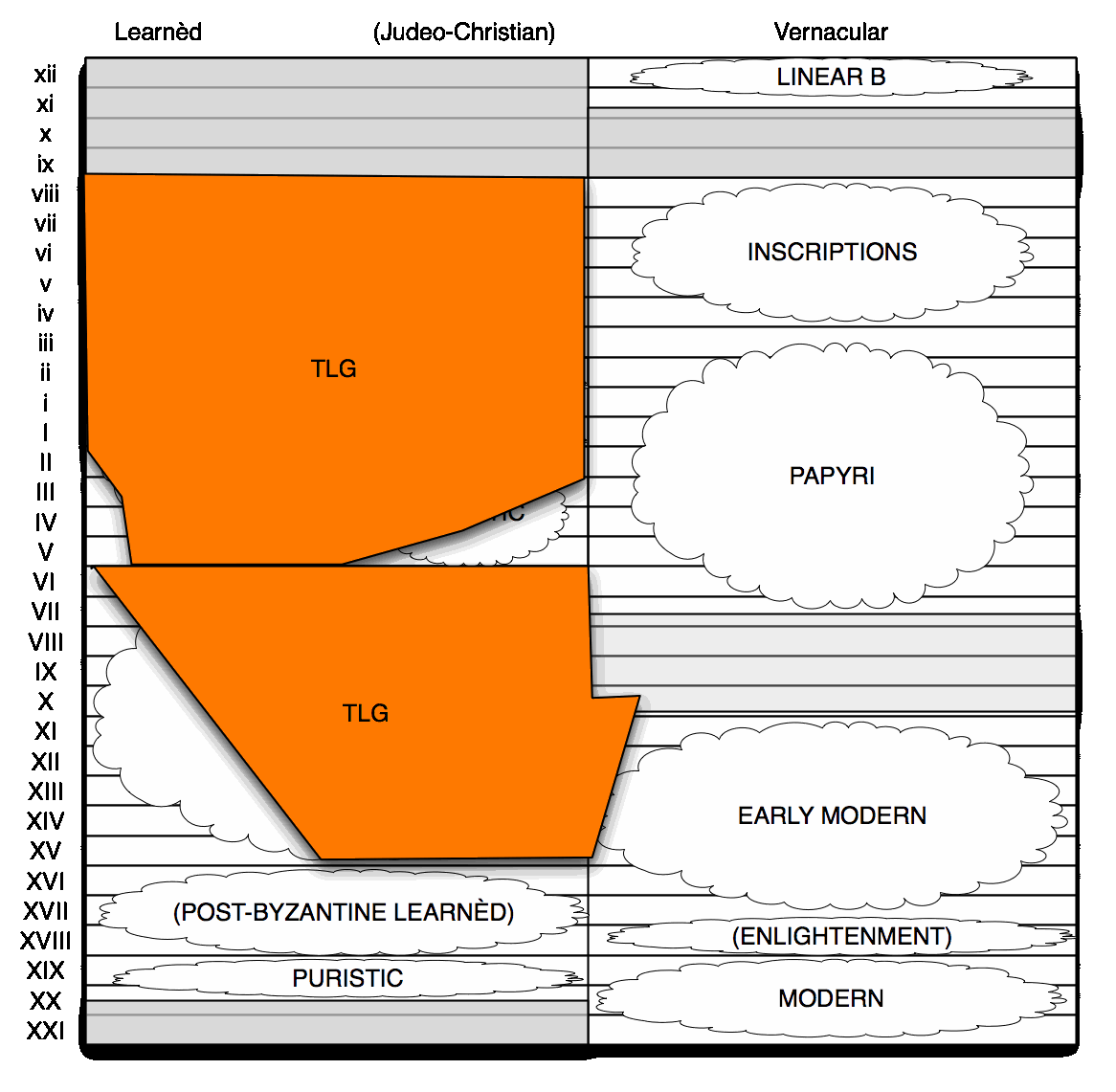
The TLG does not cover ancient non-literary texts, which are attested in papyri and inscriptions. That matters for counting words, because a lot of lemmata are only attested in non-literary sources. Non-literary sources range over details of daily life (especially in the papyri), and dialects absent from the literary canon (in the inscriptions). Non-literary texts are where texts keep showing up from antiquity, and where both the LSJ Supplement and the Diccionario Griego-Español get many of their new lemmata from.
This area is not covered by the TLG, with only a couple of exceptions (Epistulae Privatae); to address that, I'm also including the PHI #7 disc from the Packard Humanities Institute in the corpus.
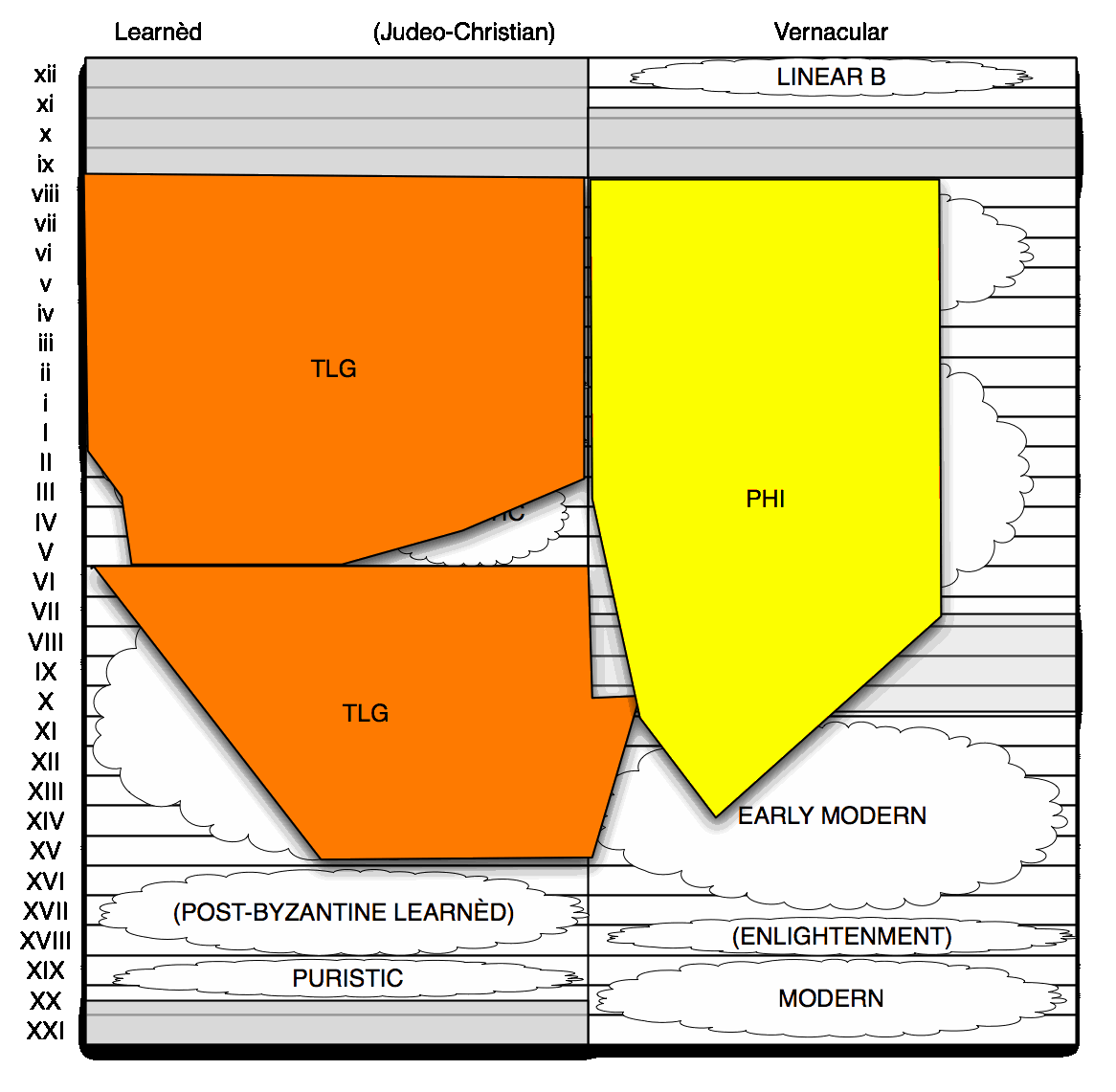
The PHI #7 disc, which has 6.5 million words of Greek, was issued in 1995, and it includes three collections: a corpus of ancient inscriptions [now online], compiled by Cornell and Ohio State Universities (3.1 million); the Duke Databank of Documentary papyri (3.1 million) [also online]; and Inscriptions of the Christian Empire, compiled by John Mansfield of Cornell (0.3 million). New inscriptions and papyri keep showing up all the time, so PHI #7 does not cover everything we know we have; but it is representative enough.
The TLG does admit non-literary texts for the mediaeval period. The monastic acts in particular are diplomatic editions (i.e. preserving the original spelling of these monastery legal documents in all their inventive confusion). Their misspellings cause our counts of word forms all manner of trouble, as we'll see. But the TLG has not been working on mediaeval inscriptions either, so PHI #7's Christian inscriptions fill in a gap as well. The Christian inscription corpus is small, but it covers a lot of ground: the proto-Bulgarian inscriptions are here, and the texts go late enough include Χακῆ as a rendering of Hajji.
For literary texts, the TLG is pretty much complete for antiquity, strictly defined. There are some gaps for the early Christian era, which are currently being filled in: the TLG is still missing some apocrypha, liturgical texts, and the Hexapla, including the Hebrew Scripture translations of Aquila and Symmachus. In terms of raw lemma count, the Latin–Greek glossaries are not in yet; when they are added to the TLG, they will account for something like a thousand LSJ lemmata currently absent from the corpus.
That an ancient dictionary should have so many one-off lemmata in it is no surprise: dictionaries contain words that people didn't know, and which are unlikely to turn up anywhere else. Which is why Hesychius is so important to comparative linguistics—and such a pain to do anything sensible with in lemmatisation. The Latin–Greek glossaries are a mixed bag: they contain words never heard of before or again (e.g. τηκεδονικός, -ή, -όν tabificabile); but they also have the first instances of common modern words (e.g. τζάπιον, τό bidens, ligo, raster—i.e. Modern τσάπα "hoe").
For the mediaeval period proper, TLG work on expanding the corpus is ongoing. We have had a guess a couple of years ago that we had 70% of the texts covered by Trapp's dictionary: that would translate to some 20 more million words. The TLG has now started to include Early Modern texts as well: it has a while to go yet, but it already has 2.5 million words of the vernacular. Of course, this is (a) only a small proportion of Early Modern Greek texts, and (b) nothing about the contemporary Modern Greek language. So this corpus doesn't tell you much about anything past 1600 at the moment.
We saw in the post on the dictionary coverage of Greek that various periods do better or worse in how well they are covered by grammars and dictionaries—and how "clean" their texts are. (Way too much Migne still for editions of the Church Fathers, for one.) That's reflected in the lemmatiser I've been working on for the TLG: it deals with Ancient Greek proper exceedingly well (99.4% recognition up to Aristotle), but more patchily with Mediaeval Greek (94.6% for viii-xvi AD learnèd, as of May). These can be illustrated with degrees of certainty of recognition by the TLG lemmatiser, something I'll talk more about later. (And note that these figures change month by month, as the lemmatiser is improved.)
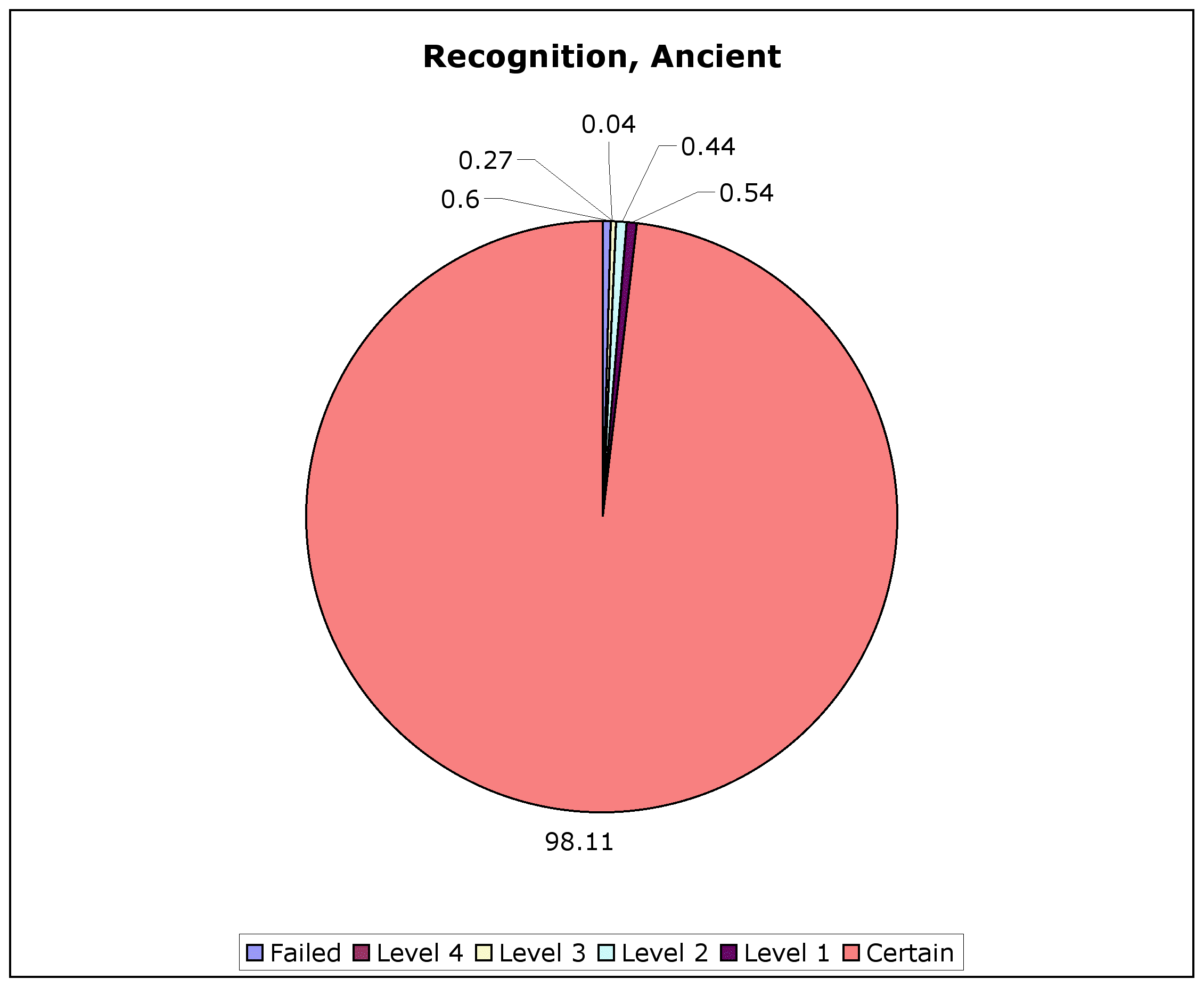
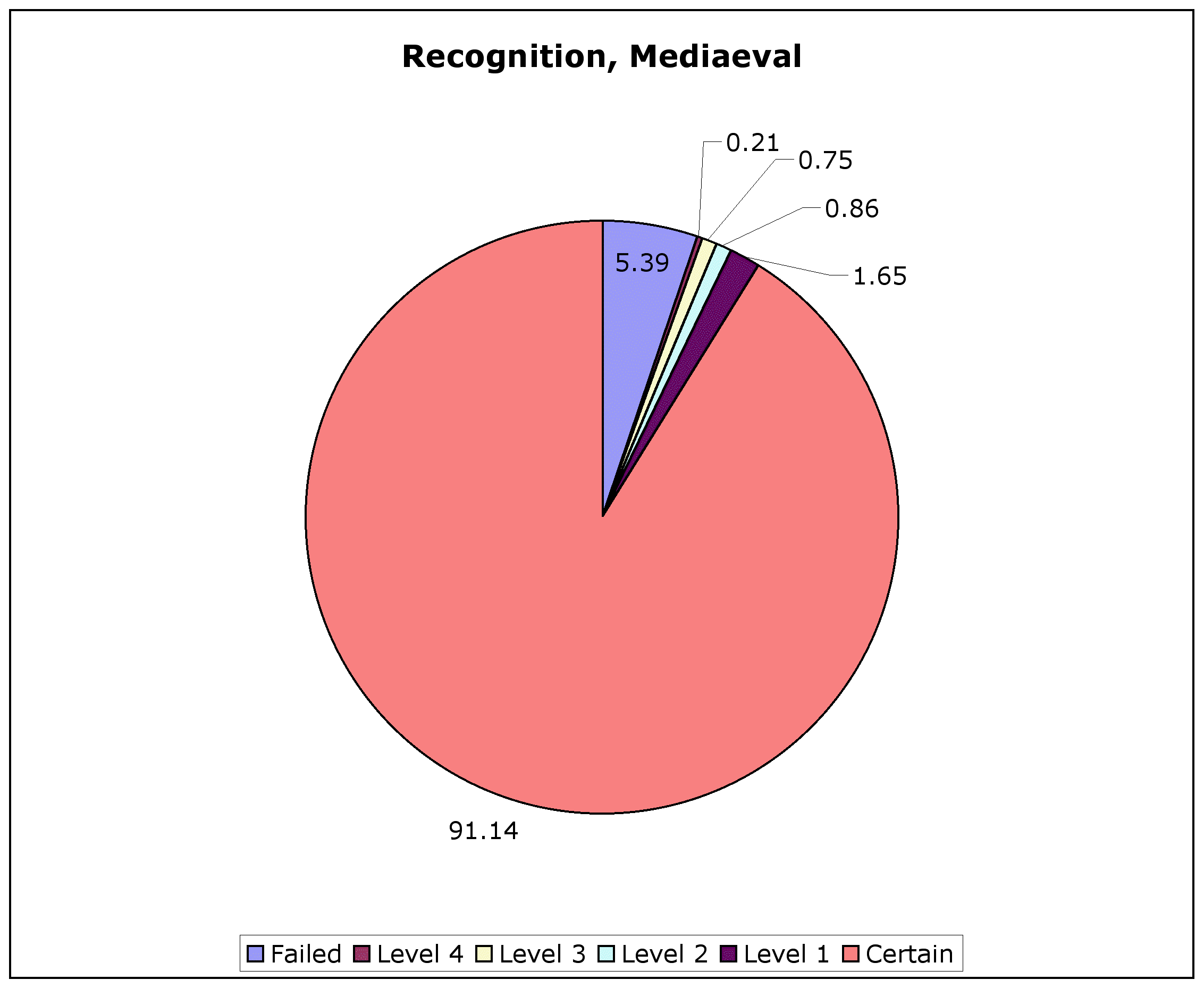
Lemma recognition is at a loss with the PHI #7 texts (around 65%). In large part, that's because of the more chaotic spelling used in those texts. In at least some part, that's because I've spent 6 years tweaking the lemmatiser to TLG texts, and only a couple of hours tweaking it to PHI. I'm missing a whole lot of inscription- and papyrus-specific lemmata from DGE (where the growth spurt is), and there's a whole lot of Egyptian proper names the lemmatiser hasn't heard of, so PHI is going to be underrepresented in any lemma counts I try to work out.
Moreover, we saw in more recent posts that the longer the time span of a corpus, the more incoherent any counts are. Given that later Greek is less well documented, less well edited, and less Classical than earlier Greek, I'm going to split my corpus in four, and give counts for each, moving progressively closer to the Ancient core. So:
- Counts for TLG + PHI #7.
- Counts for just TLG, which I've had more command over than the PHI #7 corpus (and which concentrates us on literary texts for antiquity)
- A Mostly Pagan Mostly Ancient corpus.
- A strictly Ancient corpus.
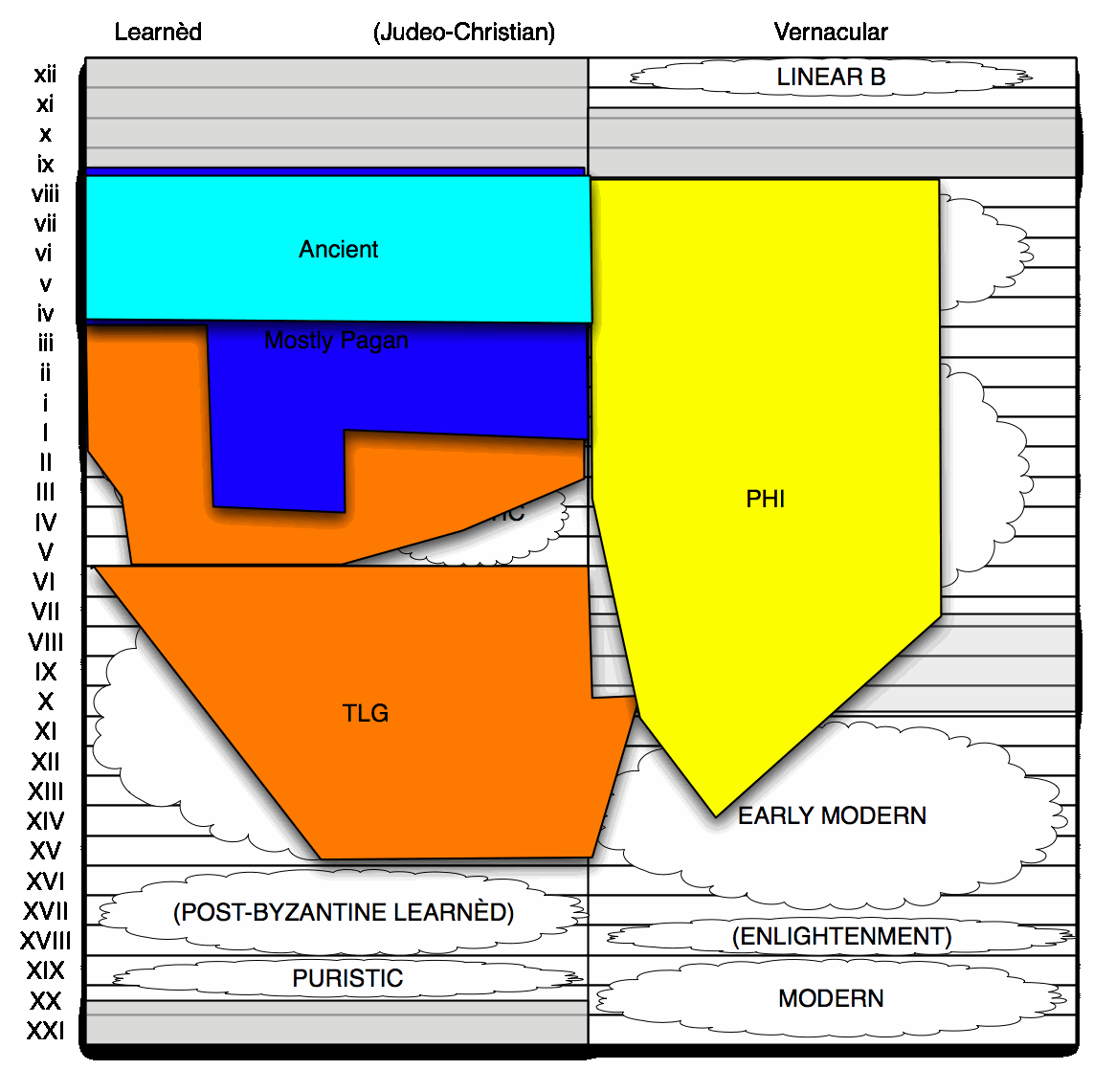
The strictly Ancient corpus stops with Aristotle, fourth century BC. That covers the classical canon, which everyone since has admired and emulated; but it's not all the texts counted as ancient in the broad sense: it leaves out Polybius, Plutarch, Lucian—and the Judaeo-Christian scriptures. Antiquity conventonially ends with Nonnus, in the sixth century AD. But having an ancient corpus go up to the sixth century will include too much "unruly" texts: texts in poor editions, or texts where the classical norms aren't as consistently observed.
To clean up the corpus somewhat, and present a middle ground between the full TLG and Homer-through–Aristotle, I'm positing a Mostly Pagan Mostly Ancient subcorpus. This goes up to the fourth century AD (so Synesius is in, Nonnus is out), and it includes the Jewish and Christian scriptures. But it excludes any other Christian writings, and technical writing: medical, legal, alchemy, astrology, lexicography, grammar, scholiastic, philology, geography, mathematics, mechanics [engineering], and magical. That's pretty brutal, but both the technical and the Patristic corpora are linguistically distinct from the literature of Lucian and Synesius, and are the kinds of text that Classicists, for better or worse, have paid less attention to. So this Mostly Pagan Mostly Ancient corpus is a literary corpus, comparable to the strict Homer-to-Aristotle grouping, but with a less straitened timespan.
Limiting the time span like that cuts down the 95 million word corpus significantly, because of how unequally texts are attested from different periods. The strictly Ancient corpus is just 5 million words large; and there are some striking disparities in how texts are represented in the TLG by century:
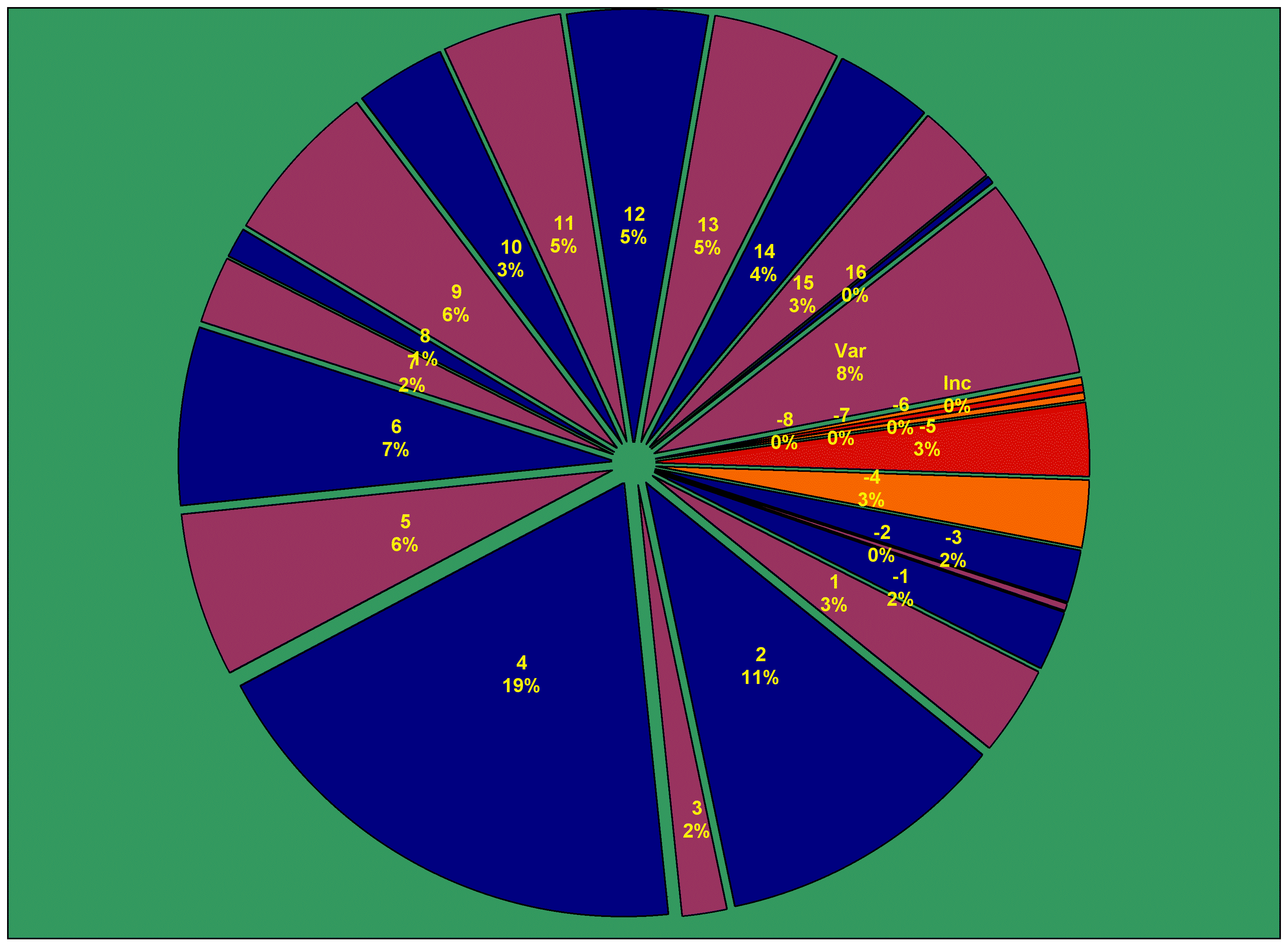
Obligatory provisos about the century breakdown: it's by author not work, so a small number of later texts get included in earlier centuries. The most egregious instance is in the Hippocratic corpus, which includes among its Ionic a text so modern, it uses Italian words for "virtue" and "colour" (βερτοῦ, κλόρε). The "Varia" are mostly scholia, which cover any time from Roman times to the late Middle Ages. But the proportions are indicative enough.
The inconsistencies will be clearer in bar chart form:
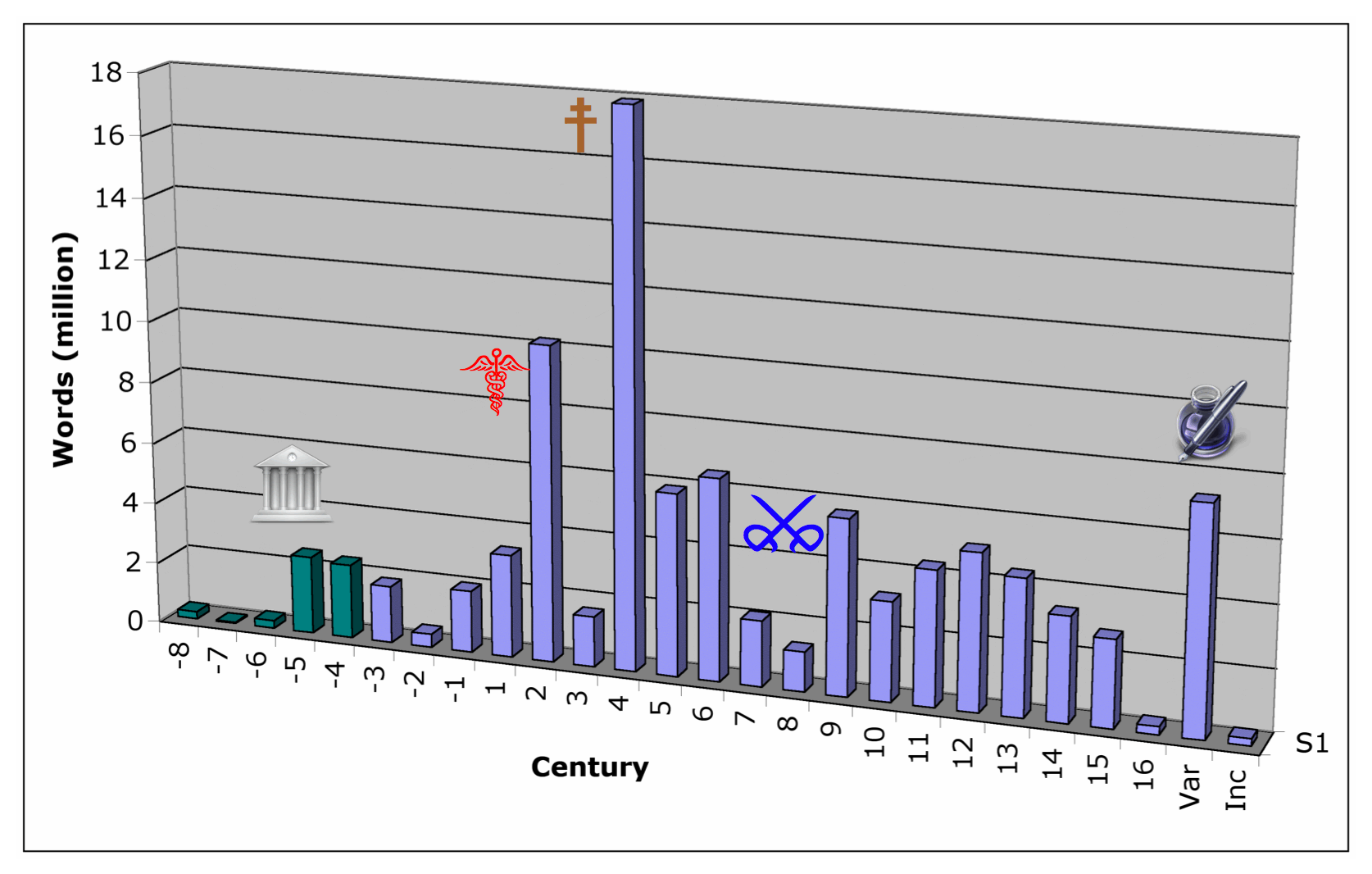
Most of the spikes in the graph can be explained. The iv AD spike are the major church fathers, and texts attributed to them—which make John Chrysostom the most prolific author in the corpus. The ii AD spike is in large measure because of the disproportionate representation of medical authors (and the Second Sophistic), and texts attributed to *them*—which make Galen the second most prolific author in the corpus. The dip in vii–viii AD is presumably the Byzantine Dark Ages (yes, yes, I know the term is problematic). The dips in other centuries, especially ii BC and iii AD, I don't really have an explanation for.
The disproportionate spikes go away if we take Christian and technical texts out of the equation, and restrict ourselves to literature (à la the Mostly Pagan Mostly Ancient subcorpus, which adds up to 19 million words).
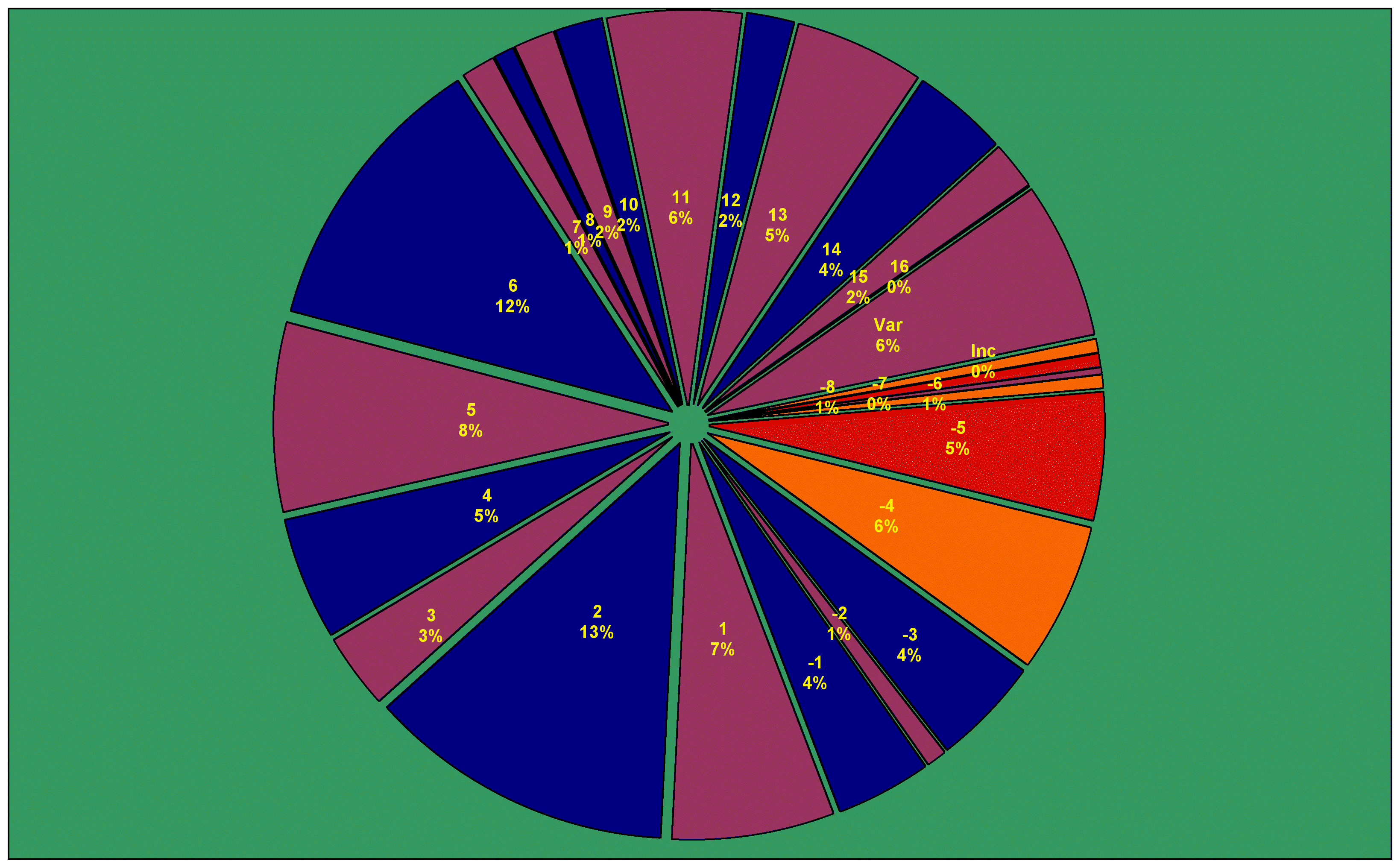
The Golden Age of Classical Literature does not look so underwhelming, for one:
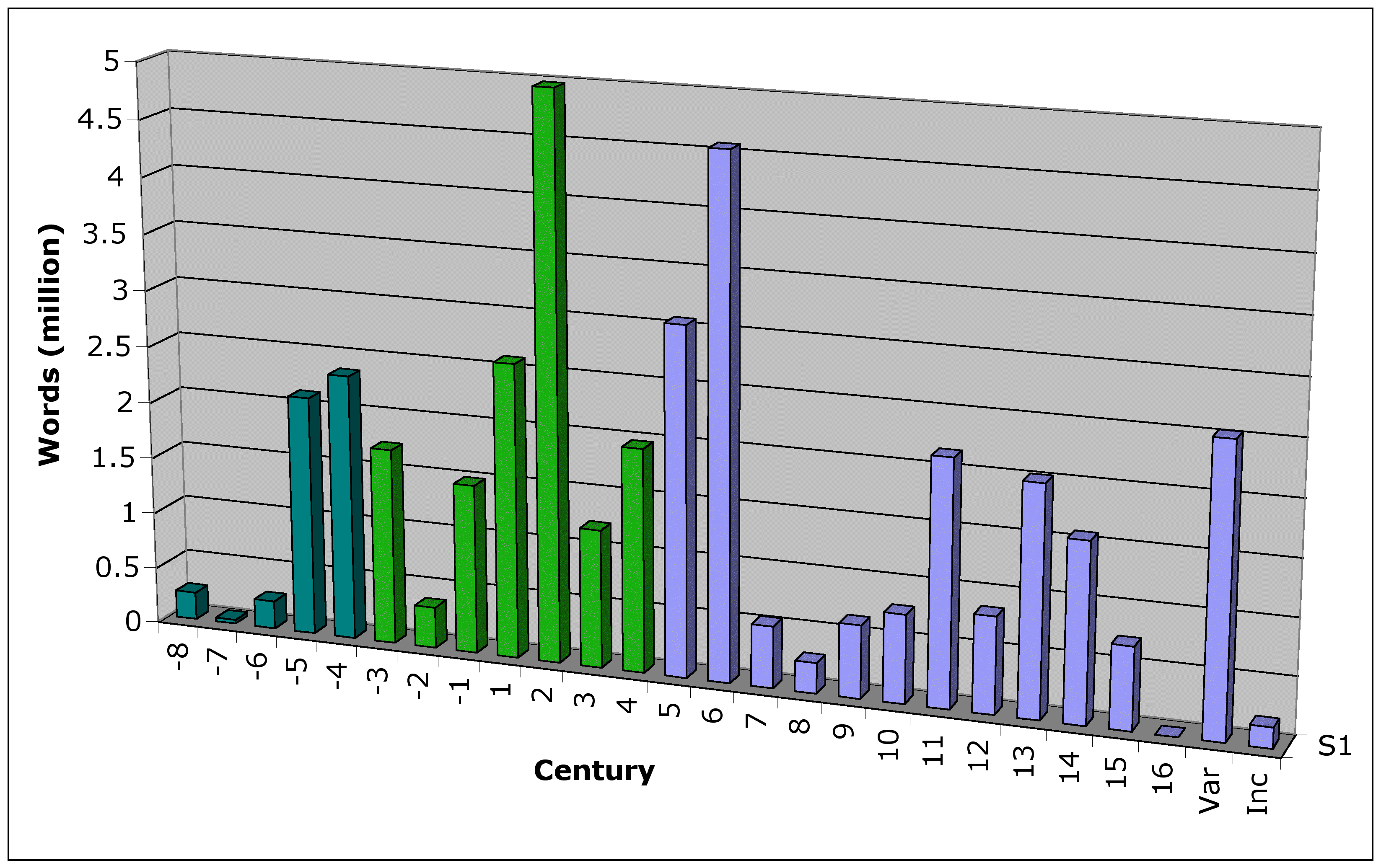
There's still some spikes that may or may not come as a surprise. vi AD is bolstered by the voluminous Neoplatonists; even without the medicos, the Second Sophistic was prolific; the Comnenan Renaissance and Palaeologan Renaissance, xi AD and xiii AD, are now visible. And once the Byzantine legal texts are taken out of the picture, the Dark Ages look Darker: they weren't as dark a time for lawyers...

 Loading...
Loading...
0 comments:
Post a Comment