At long last, after nine posts of teasing, will I finally give the punters a count of lemmata of Greek?
Why yes. Yes I will. And then for a change, I will also set to work inflating it, to extrapolate from the current corpus and lexicon I have access to, to how much larger it could conceivably get.
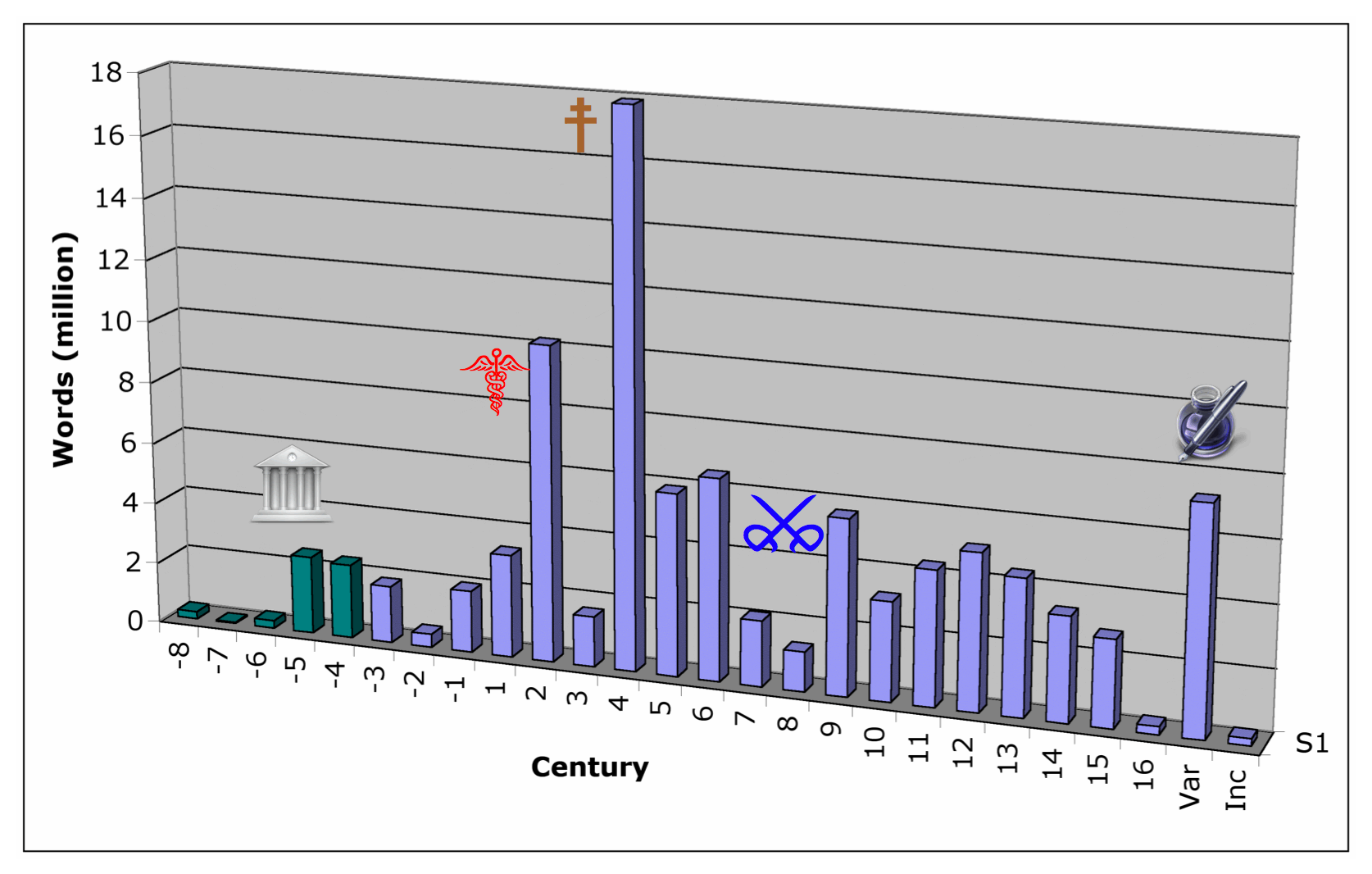
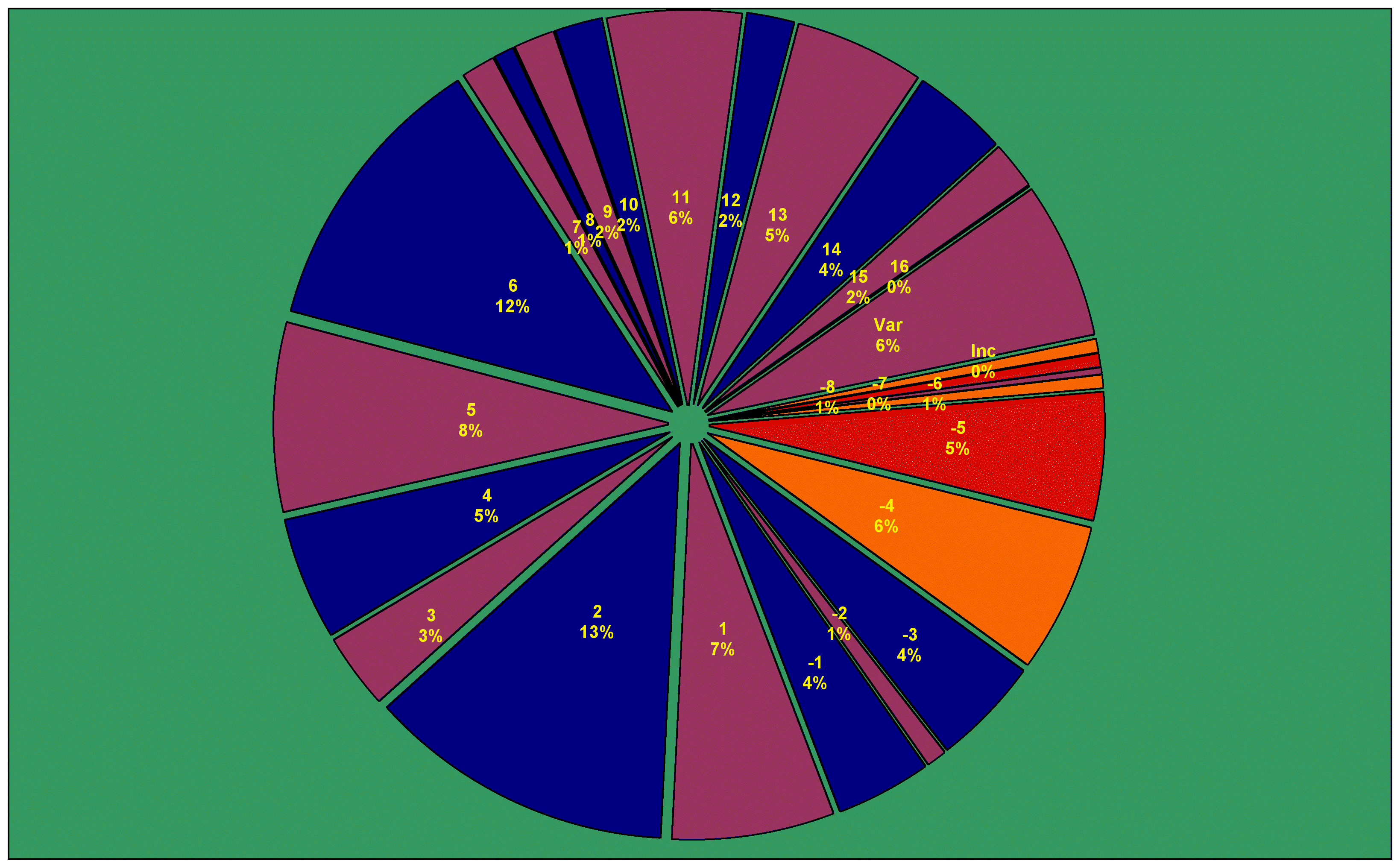
Ready for it? The count of lemmata, known to date to the TLG lemmatiser, and recognised in the four corpora we've set up as they stand to date, is...
| Lemmata | Excluding Greek Numerals | Excluding Proper Names | |
|---|---|---|---|
| TLG + PHI #7 | 216,234 | 211,794 | 175,791 |
| TLG (viii–XVI) | 201,680 | 197,448 | 162,219 |
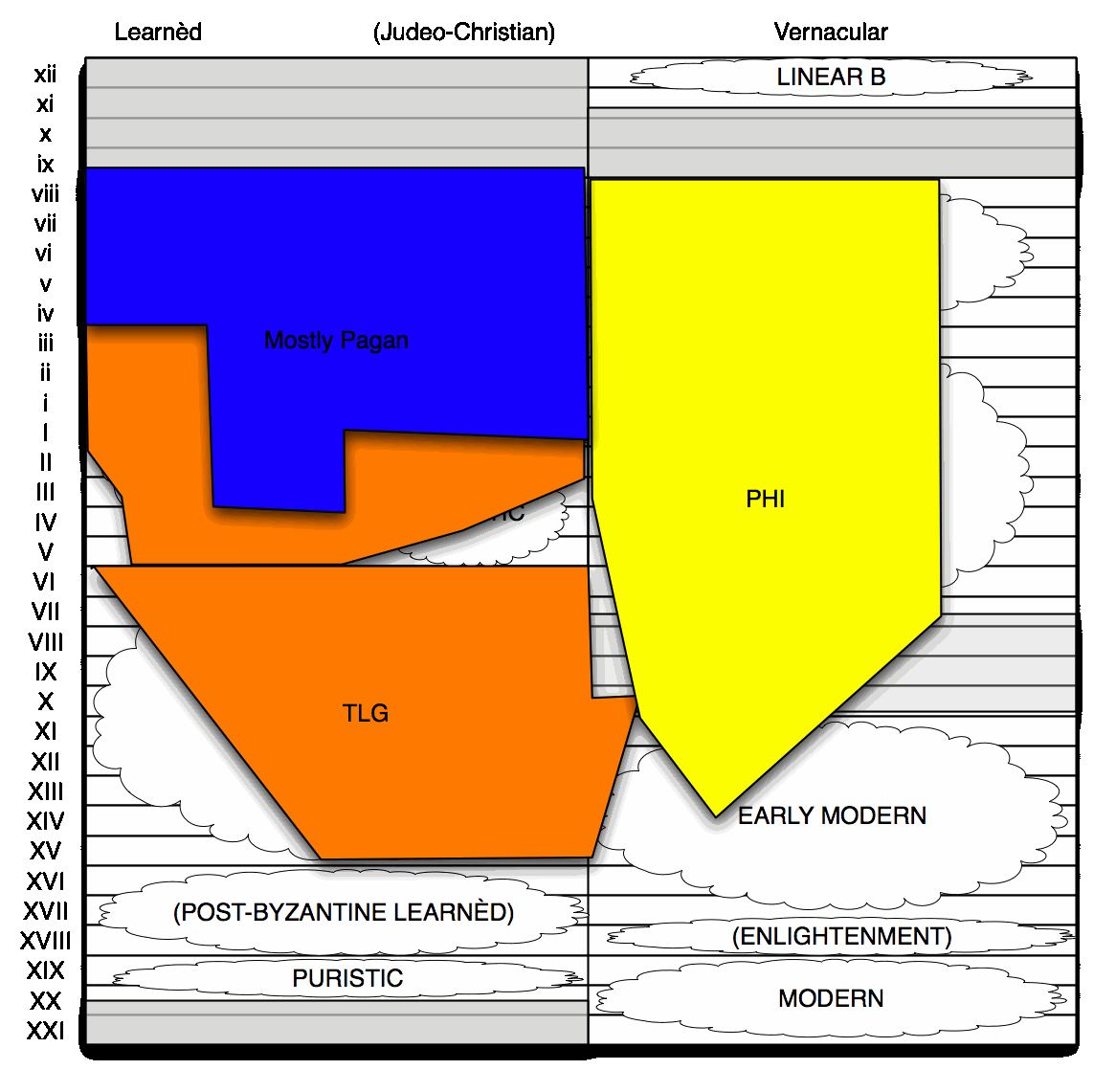
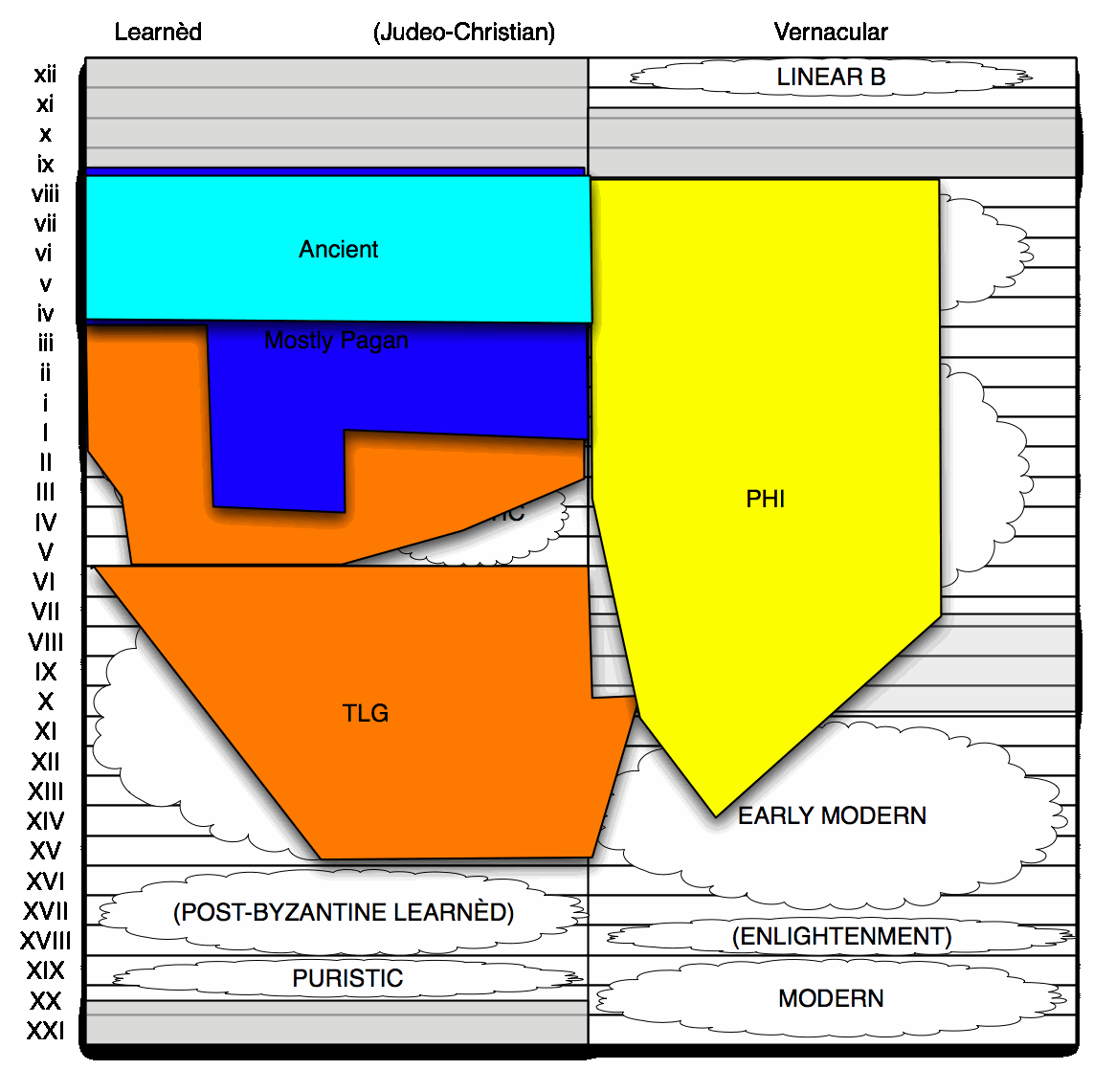
| Mostly Pagan (viii–IV) | 99,426 | 98,593 | 76,145 |
| Strictly Ancient (viii–iv) | 66,437 | 66,078 | 55,003 |
1: Lemma Counts
Did I have to quibble even here? Why, of course I did. The lemmatiser makes sense of Milesian numerals like αϠοα = 1971 and χξϛ = 666, but including them in the vocabulary of Greek as lemmata is a bit much. And dictionaries do not include proper names. So if you're going to compare the headword count in LSJ with the headword count in OED, you won't be including proper names in your count. Proper names are not exactly open-ended in count, but they do work differently from core vocabulary, they come from a lot more sources and cultures, and knowing lots of people doesn't really prove your vocabulary is more expressive.
So if we're comparing the TLG corpus to the OED's, we'll say 162,000. OTOH, adding proper names is most of my fun with the TLG lemmatiser: Athenian courtesans one minute, Albanian chieftains the next. In terms of the lemmatised search engine, they are search targets like any other. So if we're not comparing the TLG corpus to any dictionaries, we'll say 202,000 lemmata.
Not So Fast!
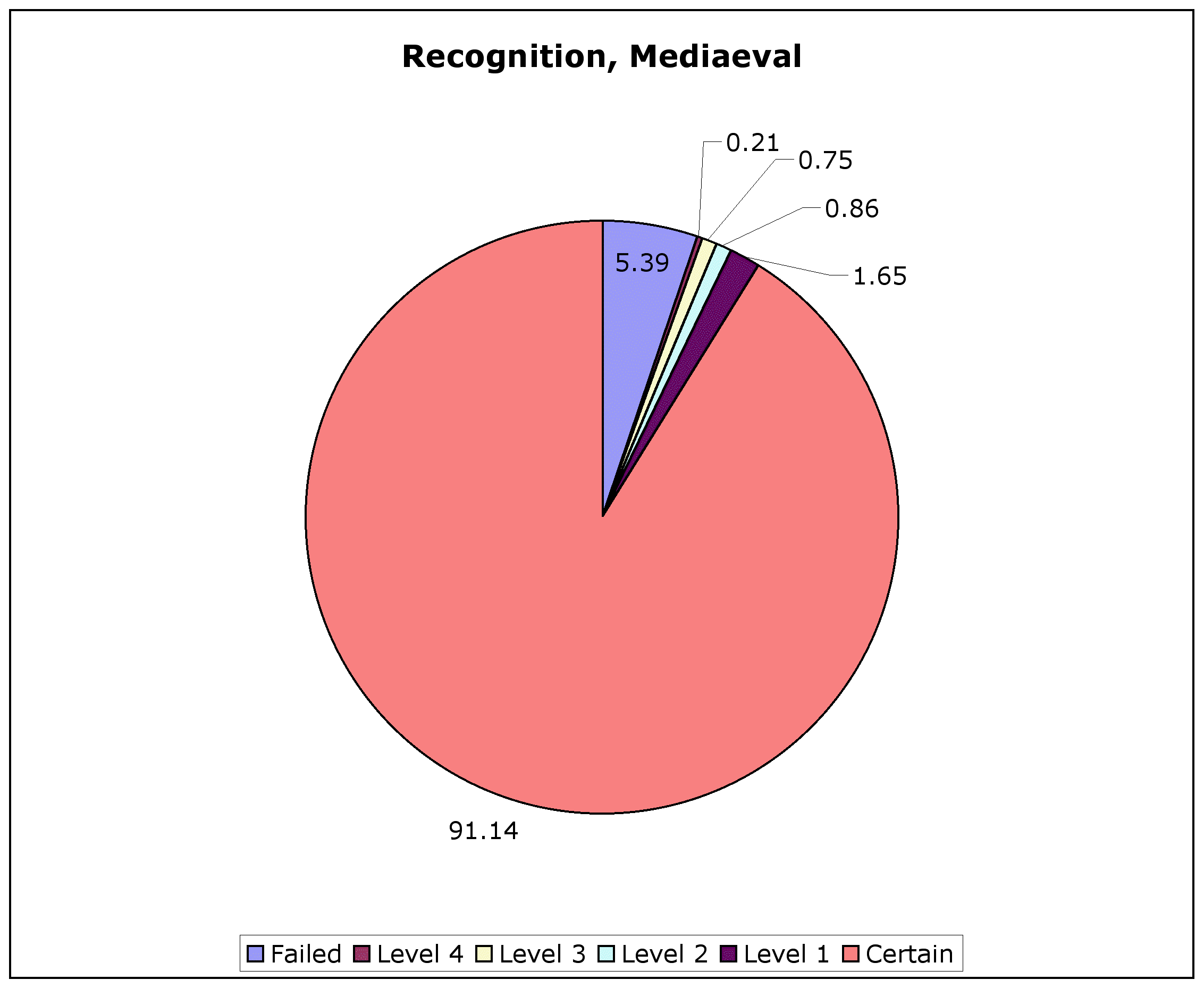
Only if you'd asked me two years ago, I'd have told you 231,000. And that was when I was recognising 90% of all word forms—as opposed to now, when I'm recognising close to 94%. Does that mean the Greek language has lost 25,000 lemmata in the intervening two years, even as the lemmatiser now recognises 60,000 more word forms? No. The lemmatiser has just gotten more discerning about when it claims a new lemma has shown up.There is a lot of ambiguity in dealing with three thousand years and six dialects of Greek, and incomplete dictionaries. The lemmatiser has been allowed to make up its own lemmata (more on this below); it does this to cover gaps in dictionaries, whether they've gotten to pi or omega. But in the past two years, the lemmatiser has been constrained to make up a new lemma only if it doesn't have a "legitimate" alternative, already recorded in a dictionary.
The lemmatiser has also gotten better at conflating variant stems under the one lemma. That's a huge issue, which will have to wait for a couple of posts: the number of stems I count as distinct lemmata is in several ways different to the number LSJ counts as being distinct lemmata. There are 216,000 lemmata in the overall corpus, following the lexical database's definition of when two stems belong to different lemmata. But its definition will be different to someone else's definition. As we'll see, it's not always clear from the dictionaries when they consider two lemmata distinct, or whether they should when they do.
All this should make you distrustful of any lemma counts I give you. As well it should. Counting lemmata is an artefact of how you set about counting lemmata; different criteria, and different methods of analysis, will give different results. As will different sizes of corpora. So in this and the next couple of posts I'm going to stretch the lemma count, then shrink it, then stretch it again. (And then I'll bring this thread to an end; there's Mariupolitan dialect waiting to be blogged about.)
Fuzzy Boundaries
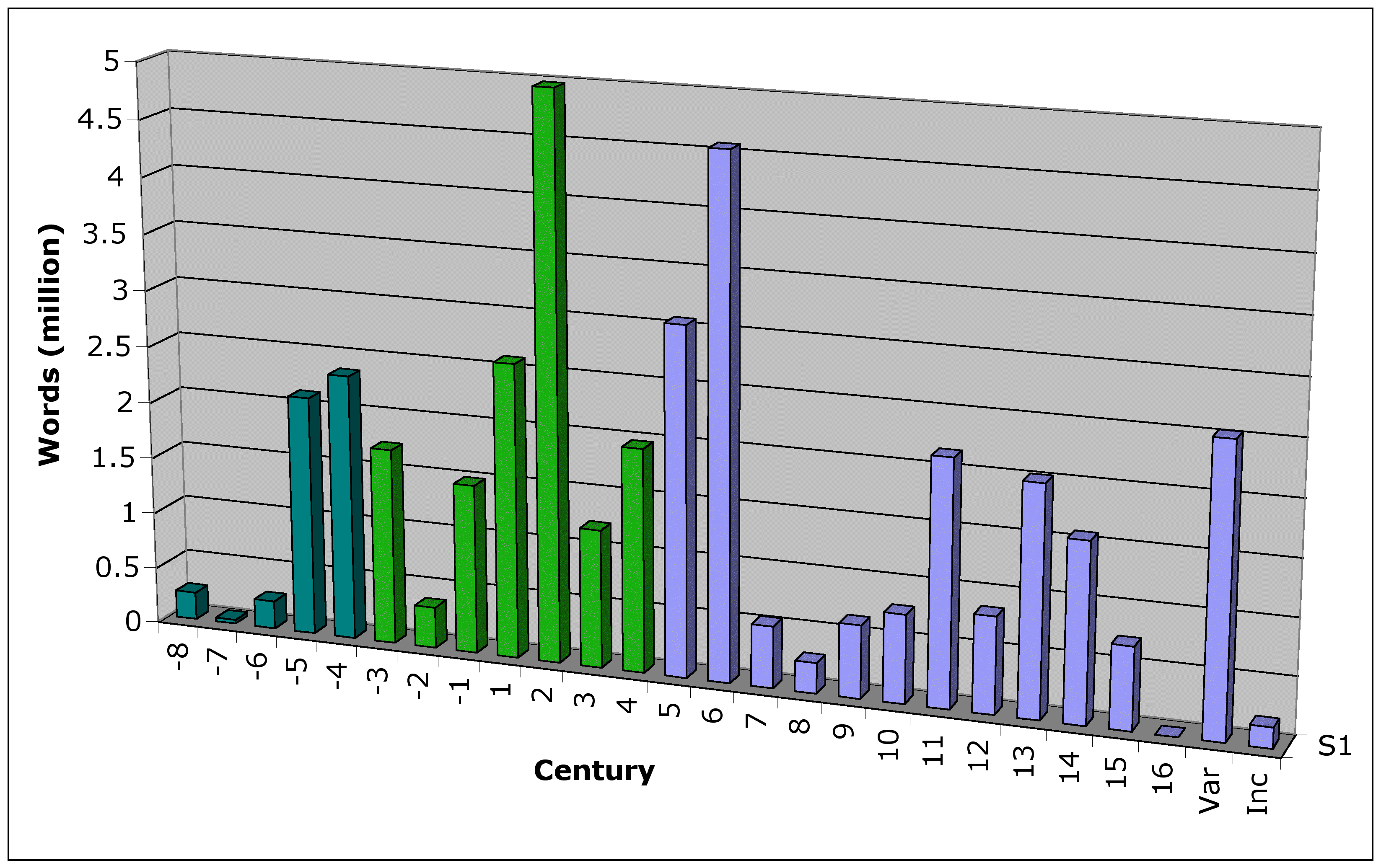
To begin stretching, I'm going to allow for the uncertainty of lemmatisation. The TLG lemmatiser, confronted with much too much ambiguity, ranks potential analyses of word forms as belonging to different lemmata. The counts I've just given are for the "winning" lemmata for each word form. If I include the "also-rans" in the analyses, then I'll also be counting lemmata which never give the preferred analysis for any word form—but which the lemmatiser keeps in reserve, in case one of them turns out to be correct after all. You will get search results if you look up those lemmata in the TLG. You will also get lots of warning, saying "but this form is probably X instead, and that form is probably Y instead."If I include these also-rans in the counts, the counts go up to:
| Lemmata | |
|---|---|
| TLG + PHI #7 | 220,560 |
| TLG (viii–XVI) | 206,161 |
| Mostly Pagan (viii–IV) | 107,257 |
| Strictly Ancient (viii–iv) | 73,427 |
2. Lemma counts, including also-ran analyses
This gives a curious result. There are lemmata which the Strictly Ancient corpus rejects as implausible for all its forms; but somewhere in the subsequent mediaeval morass, a word form turns up for which the rejected lemma makes the most sense after all. Of course, a lot of those lemmata rejected for Strictly Ancient Greek will turn out to be Byzantine after all. So it makes sense they'd become more acceptable, once bona fide Byzantine texts are included.
More dictionaries
There are two constraints on what a lemmatiser recognises: how many words it knows about, and how many words you're asking it to recognise. Increase the corpus—as we did by excluding and including Byzantine texts—and it will find more lemmata. Give it more dictionaries—as the TLG did by adding Lampe, Trapp, and Kriaras—and it will also recognise more lemmata. So these counts could be bigger with more texts (and more texts are being added), and more dictionaries.You can increase your dictionary size by allowing the lemmatiser to do what human beings do: make words up. You can make words up from whole cloth, as a random but plausible sequence of sounds. But that's fairly rare in human language. What is much more usual is making up words based on existing words, using rules present in the language (derivational morphology). The lemmatiser does know something about Greek derivational morphology: as a result, the TLG counts include some 15,000 lemmata that are not in its dictionaries, but are derived from lemmata that are. Two thirds of these are from prefixing prepositions to verbs, which is quite productive in Greek. One third is from derivational morphology forming new stems through suffixes, and those proposed analyses are more tentative.
But derivational morphology will only catch some words. Otherwise, if a lemma is unrecorded in the dictionaries that the lemmatiser has access to, then that lemma won't show up in the list of lemmata recognised: you have to tell the lemmatiser that πιθανοθηρία exists, for it to make sense of πιθανοθηρίας. If you give the lemmatiser access to more dictionaries, it will recognise more words.
Much of the TLG is Byzantine, and more of the TLG is going to be Early Modern; so the fact that the dictionaries of both stages of the language are currently stuck at pi means there are future volumes of those dictionaries that the lemmatiser hasn't been given access to yet (because they don't exist). That means a lot of lemmata in the corpus going unrecognised, and being missed in these counts.
My back of an envelope can beat your back of an envelope
How many? Here start the back of the envelope calculations: take them with several satchels of salt. Trapp has finished six volumes out of a projected eight, and adding Trapp's lemmata to the lemmatiser has accounted for 25,000 lemmata newly recognised in the TLG. The remaining two volumes (to be completed by 2013) should add another 8,000 lemmata to the TLG. So 202,000 will go to 210,000—give or take a couple of thousand. Remember those 15,000 lemmata the lemmatiser is recognising, even though they're in no dictionaries? Some of them will turn up in the forthcoming volumes of Trapp.The same holds for Kriaras. With the 2.5 million words of Early Modern Greek in the TLG, adding Kriaras' dictionary to the lemmatiser accounts for 2650 lemmata. Since Kriaras is up to 15 volumes of a projected 19, that would mean we're owed another 550 lemmata. Except, the TLG is not going to stay at 2.5 million words of Early Modern Greek: it's expanding deliberately into the Early Modern corpus, and there'll be a lot more lemmata added to the TLG as it does so. The 15 volumes of Kriaras have added 9900 lemmata to the lexical database, so with with the 2650 already seen in the corpus, we can expect another 9900 lemmata once the entire Early Modern corpus is in and Kriaras is completed. That takes us to 220,000 lemmata.
In fact, because we haven't run out of Byzantine learnèd texts to data enter into the TLG corpus either, 8,000 more lemmata from Trapp is an underestimate. There are 35,000 headwords in Trapp that the TLG does not already recognise from its other dictionaries; but the current corpus only accounts for 25,000 of them. There's some spelling variation and derivational morphology clouding the results, but all up, and assuming headwords and lemmata are the same (which they're not), we should expect not 8,000 more lemmata once all the texts are in (and all the spelling variation accomodated for), but 20,000. That takes us to 232,000 lemmata.
"A headword is not a lemma"?! But the definition of "lemma" *is* "headword"! I'm being a little idiosyncratic in my usage: the source dictionaries each have their own headwords, but I'm calling "lemma" the canonical lexeme that the lemmatiser uses, to bind those headwords and variants together—in case it merges two different headwords from its sources into the one lexeme. In other words, I distinguish dictionaries' print "headwords" from the lemmatiser database's "lemmata".Even with Strictly Ancient Literary Greek, there are word forms that the dictionaries are missing, because editions have changed, or new fragments have turned up, or lexicographers (who often copied each other) had a blind spot. The DGE do use the TLG to compile their list of words, so there's a good chance they'll catch the gaps in the TLG corpus at least. But the corpora are fluid, for reasons we've already discussed. So πιθανοθηρία "hunting for possibilities" turns up as a variant reading in Plato's Sophist; because it's a variant reading, lexicographers have not been panicked to include it. The dictionaries don't (yet) register anything that deals with ὀκταχοίνικον "eight choinixes heavy" in Aristophanes, or πεντηκοντακισμυρίους "five hundred thousand" in Polybius. (That's the other blind spot of lexicographers: numbers are boring.)
The count of missing lemmata won't be massive for antiquity: there are currently just 1,600 word forms unrecognised in the Strictly Ancient corpus, and from inspection, skipping proper names and geometric lines, there'll be a lot less than 500 lemmata's worth there. Still, 500 is 500; and it's thousands, not hundreds, of skipped lemmata moving forwards from Strictly Ancient to Mostly Pagan. Moreover, there are a couple of late ancient texts that, once added, will give us a lot of lemmata: we're owed 1000 lemmata from the old Latin-Greek dictionaries, a couple of hundred from the Hexapla.
PHI #7 has even more treasures to unlock—although it'll have to be someone else's job to do the unlocking. Remember that Vol I of the DGE in the second edition has 3500 lemmata not in LSJ, from α to ἀλλά; extrapolating, that would mean around 80,000 lemmata all up not in LSJ, if and when DGE finishes. How many of those lemmata are already going to be in Bauer, Lampe, and Trapp? My guess is, a fair few; DGE is nowhere near as Pagan-centric as LSJ.
But there are also lemmata specific to the inscriptions and papyri, and not recorded elsewhere. The lemmatiser failed to deal with 40% of the 300,000 word forms unique to PHI #7; and that corpus is not the latest and greatest in papyrology and epigraphy. With 6 word forms per lemma in the Strictly Ancient corpus (which has about the same number of forms), that could mean 20,000 more lemmata unaccounted for. I'm sure that maths is completely wrong, but let's pretend it's not: that would mean that, if Kriaras, Trapp, and DGE were completed and added to the TLG lemmatiser, the overall lemma count for PHI #7 and TLG would go from 216,000 to 268,000. Give or take several thousand and more and more satchels of salt.
Keep going? The Triantaphyllidis dictionary of Modern Greek (the contemporary language) has around 47,000 headwords. There'll be substantial overlap with LSJ, let alone with Kriaras. Maybe 10,000 more? Maybe 15,000? And there's the dialects of Modern Greek to count too. It's starting to look like all the lemma of any form of Greek ever spoken anywhere will be around 300,000.
And is that count meaningful? Of course not. Modern Greek is borrowing words from English all the time. (Some of them, it even spells with Greek characters.) And if I did a lemma count for every Italic language spoken over the same time span in the general area of the Apennine Peninsula—from Iron Age South Picene through to modern Bulgnais, via Latin, Standard Italian, and a lot more than six literary dialects in between—then I'd probably get more than 300,000. And of course, any lemma count spanning more than a century is not linguistically kosher anyway. But hey, people ask.
(Bulgnais? The dialect of Bologna. Sounds like Provençal with a head cold. See description in Bulgnais.)
Back to LSJ
You may have noticed that I was only half-heartedly using counts of dictionary headwords in all of this, even though dictionary writers have a bigger corpus than I do, and a more authoritative sense of what should count as a headword. Mapping headwords to lemmata is more complicated than you might think, especially if you're spanning millenia.For instance, are ἀνήρ and άντρας the same lemma? We've decided they are. But the headwords look completely different, because they are two thousand years apart. And this doesn't just happen going from Ancient to Modern Greek; it happens from Ancient to Byzantine Greek, and even between Ancient dialects. So there will be less lemmata than headwords. On the flip side, some variants in the printed dictionaries are being treated as separate lemmata, because there's no consistent indication when they're variants and when they're more loosely related forms.
For the record, I'll note that the 1940 LSJ has 122,000 headwords by my reckoning, and 6,000 of them are cross-references; that leaves 116,000 headwords. The LSJ supplement of 1996 has an additional 10,000 headwords, which makes it 126,000. These headwords span the Mostly Pagan corpus (75,000 lemmata that aren't names or numbers), plus the inscriptions and papyri (at least 10,000 more lemmata), plus a bunch of technical vocabulary that I'd skipped in excluding Galen and his fellows. If I put Galen and his fellow technical writers back in, but I still leave out the Church Fathers (like LSJ does), and I also add in the papyri and inscriptions from PHI #7 (but not the "Christian Empire" inscriptions), then I get a corpus pretty much like LSJ's corpus. And my lemma count for that corpus, leaving out numbers and names, is 98,333.
98,333 isn't 126,000; but then, lemmata aren't the same as headwords, some LSJ lemmata have disappeared with new editions, we're missing a few late ancient texts, the lemmatiser is really struggling with understanding inscriptions. In addition, the lexica of Hesychius and Photius alone, which are outside the Mostly Pagan corpus (but document older stages of Greek) account for close to 9000 headwords in LSJ, and well over 1000 for the LSJ Supplement. With them taken out, 98,333 is certainly in the same neighbourhood as 116,000.
I'll have more to say about headword-to-lemma mapping in a couple of posts, anyway.
For Zeus' Sake, How many lemmata of Greek?
So. With the evidence available to me right now, with the current status of the TLG corpus and lemmatiser, and my satchels of salt, and OK, OK, enough already...- How Many Ever? Depending on how long a time window you put, and whether names count or not, anything from 55,000 to 300,000.
- How many lemmata of Ancient Greek? Depends again, but if names don't count, and we allow Synesius and not St Athanasius—i.e. LSJ's Pagan-centric definition of Ancient Greek—then 98,000 is a reasonable first guess. Though the way DGE is going, and with new material showing up in the sands of Egypt, add maybe 20,000 lemmata to that.
- How many lemmata of Literary Ancient Greek? Depends for a third time, but if time didn't stop with Aristotle but Synesius (and names still don't count), 75,000. If time did stop with Aristotle, 55,000.
- If names count, Ancient Greek goes up to 124,000. Literary Ancient Greek goes up to 99,000. Homer-to-Aristotle Greek goes up to 66,000.
No, that's not a straight answer. You want a straight answer, don't do lexicography. And in the next couple of posts, I'll complicate the answer more again. ...Read more













 Loading...
Loading...